「算」 06. KMP 算法
本文最后更新于:5 个月前
以 leetcode 28 题为例,学习一下 KMP 算法。本文参考 Carl 的教程。
题目介绍
给你两个字符串 haystack 和 needle,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
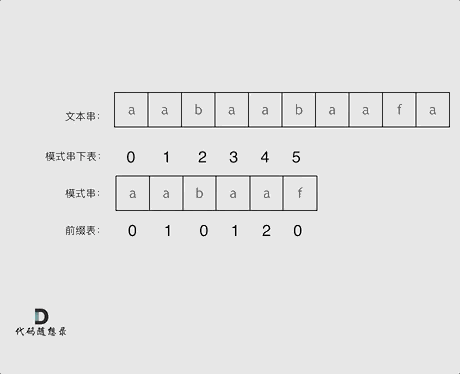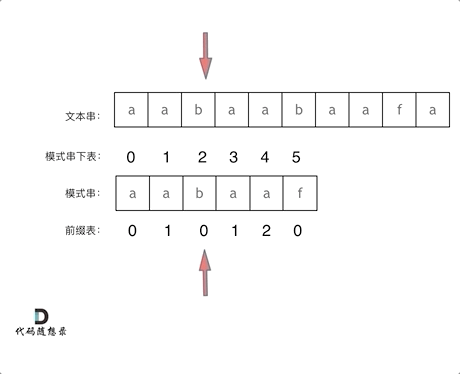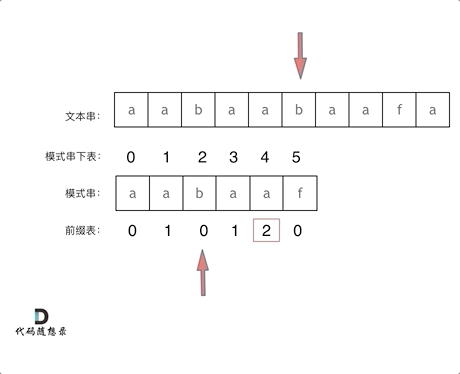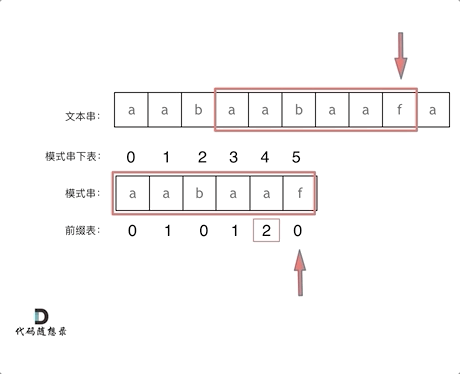
举个例子,就是要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf,并返回出现的地方。
暴力解法很容易想到,但是时间复杂度是 O(m*n) (m 和 n 分别是文本串和模式串长度)
而 KMP 算法的时间复杂度为 O(m+n) (匹配和单独生成 next 数组)
KMP 算法
KMP 是由三位学者发明的:Knuth,Morris 和 Pratt,取了三位学者名字的首字母,所以叫做 KMP。
KMP 主要应用在字符串匹配上。
KMP 的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
假设文本串有下标 i,模式串有下标 j。
可以看到整个 KMP 过程中 i 是不需要回溯的,出现不匹配时 j 会回溯到 next[j-1] 的位置,所以构建 next 是关键。
next 数组
next 数组就是一个前缀表(prefix table),记录下标 i 之前(包括 i)的字符串中,有多大长度的相同前缀后缀。
前缀表是用来回退的,它记录了模式串与文本串不匹配的时候,模式串应该从哪里开始重新匹配。
如何计算前缀表
如图:
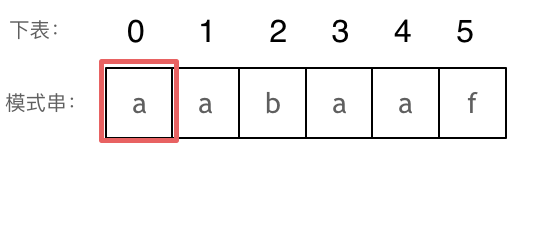
长度为前 1 个字符的子串 a,最长相同前后缀的长度为 0。(注意字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串)
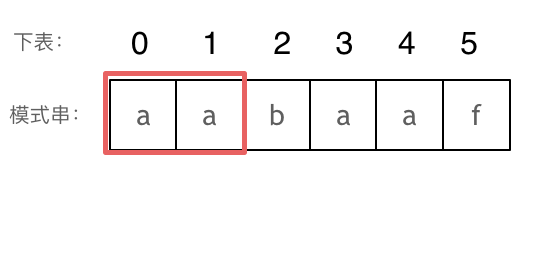
长度为前 2 个字符的子串 aa,最长相同前后缀的长度为 1。
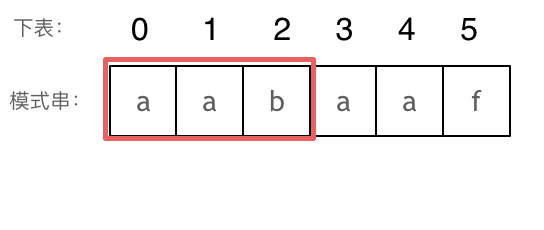
长度为前 3 个字符的子串 aab,最长相同前后缀的长度为 0。
以此类推:长度为前 4 个字符的子串 aaba,最长相同前后缀的长度为 1。长度为前 5 个字符的子串 aabaa,最长相同前后缀的长度为 2。长度为前 6 个字符的子串 aabaaf,最长相同前后缀的长度为0。
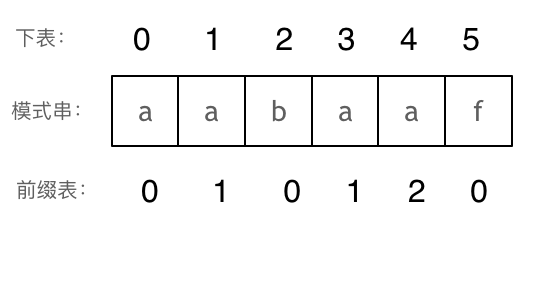
前缀表与 next 数组
next 数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为 -1)之后作为 next 数组。
其实这并不涉及到 KMP 的原理,而是具体实现,next 数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为 -1)。
构造 next 数组
构造 next 数组主要有如下三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
代码实现
这是我自己写的不右移也不减一的版本。
总结就是:i 一直往后走,遇到不匹配,j 去找前一位看看回溯到哪里。
1 | |
总结
本文只简单介绍了 KMP 算法的流程,但是关于为什么它可以解决字符串匹配的问题,没有详细讨论。感兴趣的话可以参考这篇文章。