「学」 Kubernetes
本文最后更新于:24 天前
Kubernetes 是一个用于自动化部署、扩展和管理容器化应用程序的容器编排平台。它的目标是处理大规模、高可用性的分布式系统。保证应用业务高峰并发时的高可用性;业务低峰时回收资源,以最小成本运行服务。为多个容器提供服务发现和负载均衡,使得用户无需考虑容器 IP 问题。
1 k8s 简介
1.1 主要特性:
- 高可用,不宕机,自动灾难恢复
- 灰度更新,不影响业务正常运转
- 一键回滚到历史版本
- 方便的伸缩扩展(应用伸缩,机器加减)、提供负载均衡
- 完善的生态
1.2 不同的应用部署方案:
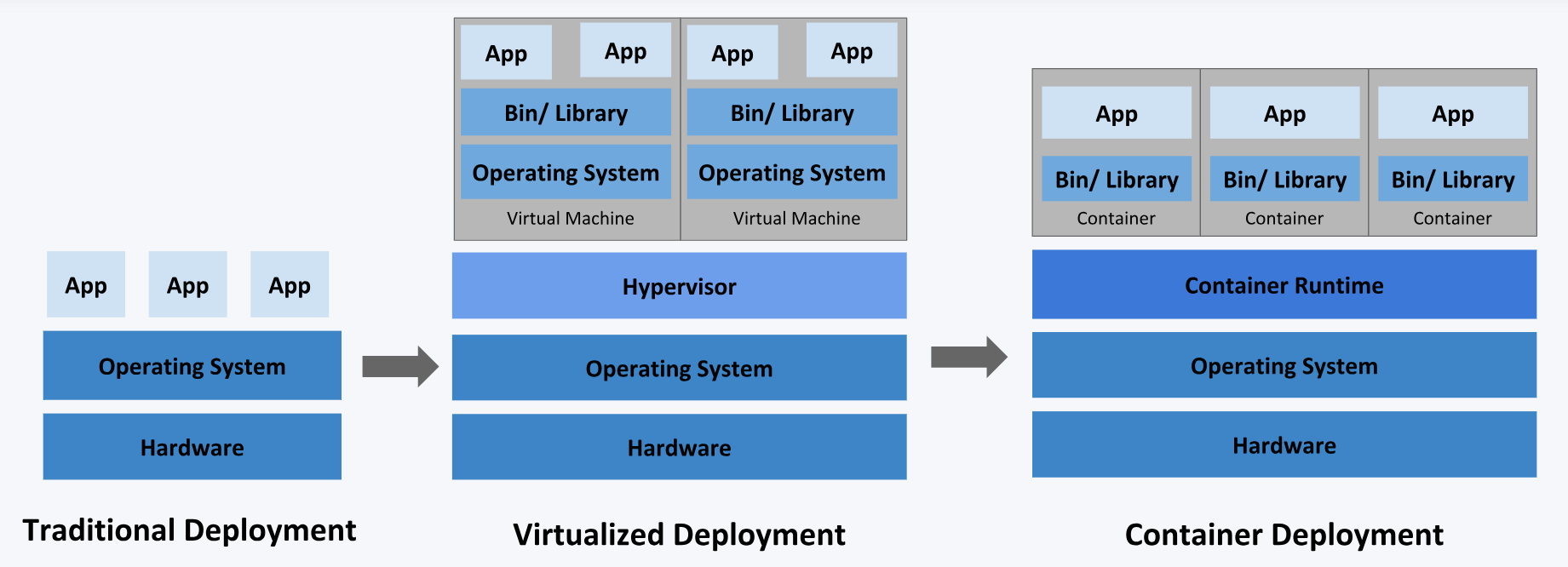
传统部署方式:应用直接在物理机上部署,机器资源分配不好控制,出现 Bug 时,可能机器的大部分资源被某个应用占用,导致其他应用无法正常运行,无法做到应用隔离。
虚拟机部署:在单个物理机上运行多个虚拟机,每个虚拟机都是完整独立的系统,性能损耗大。
容器部署:所有容器共享主机的系统,轻量级的虚拟机,性能损耗小,资源隔离,CPU 和内存可按需分配
当你的应用只是跑在一台机器,直接一个 docker + docker-compose 就够了,方便轻松;
当你的应用需要跑在 3,4 台机器上,你依旧可以每台机器单独配置运行环境 + 负载均衡器;
但是当你应用访问数不断增加,机器逐渐增加到十几台、上百台、上千台时,每次加机器、软件更新、版本回滚,都会变得非常麻烦,这时候 Kubernetes 就可以一展身手了,可以为你提供集中式的管理集群机器和应用,加机器、版本升级、版本回滚、不停机的灰度更新,确保高可用、高性能、高扩展。
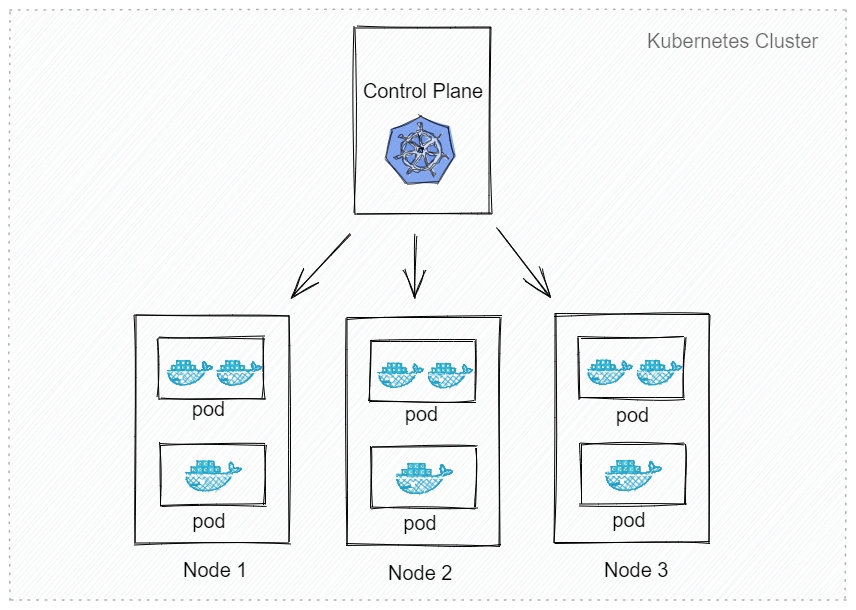
2 k8s 集群
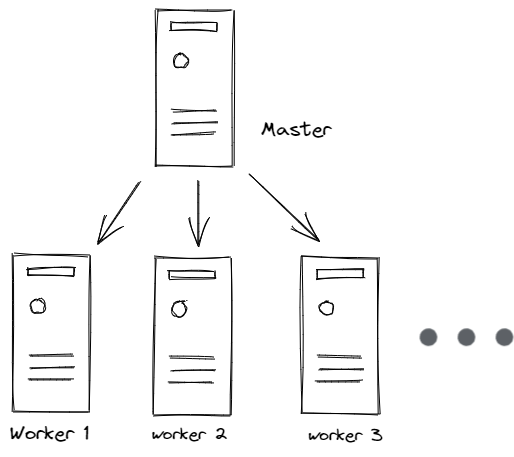
master:主节点,控制平台,不需要很高性能,不跑任务,通常一个就行了,也可以开多个主节点来提高集群可用度。
worker:工作节点,可以是虚拟机或物理计算机,任务都在这里跑,机器性能需要好点;通常都有很多个,可以不断加机器扩大集群;每个工作节点由主节点管理。
pod:k8s 调度、管理的最小单位,一个 pod 可以包含一个或多个容器,每个 pod 有自己的虚拟 IP。一个工作节点可以有多个 pod,主节点会考量负载自动调度 pod 到某个节点运行。
deployment:包含由模板和副本数(要运行的模板数量)定义的 pod 集合。如果我们有一个 deployment,其副本数为 10,其中 3 个 pod 由于机器故障而崩溃,这 3 个 pod 将会在集群中的其他机器上被调度运行起来。
service:提供一个稳定的端点,它可以用来将流量定向到所需的 pod 上,即使底层 pod 由于更新、扩展和故障而发生变化。service 基于在 pod 清单文件元数据中定义的标签(键值对)知道应该向哪些 pod 发送流量。
pod 的生命周期:
| Phase | 描述 |
|---|---|
| Pending | Kubernetes 已经创建并确认该 pod。此时可能有两种情况:1. pod 还未完成调度(例如没有合适的节点);2. 正在从 docker registry 下载镜像 |
| Running | 该 pod 已经被绑定到一个节点,并且该 pod 所有的容器都已经成功创建。其中至少有一个容器正在运行,或者正在启动/重启 |
| Succeeded | pod 中的所有容器都已经成功终止,并且不会再被重启 |
| Failed | pod 中的所有容器都已经终止,至少一个容器终止于失败状态:退出码不是 0,或者被系统 kill |
| Unknown | 因为某些未知原因,不能确定 pod 的状态,通常的原因是 master 与 pod 所在节点之间的通信故障 |
为什么要使用 pod,不直接使用容器呢?
pod 的存在主要是让几个紧密连接的容器之间共享资源,例如 IP 地址,共享存储等信息。如果直接调度容器的话,那么几个容器可能运行在不同的主机上,这样就增加了系统的复杂性。
为什么不直接在一个容器上运行所有的应用?
容器运行时(docker 等)无法监控到容器内所有应用的运行状态。每个容器中只运行一个应用程序,可以提高水平伸缩能力、复用性、便于管理其生命周期。
3 k8s 组件
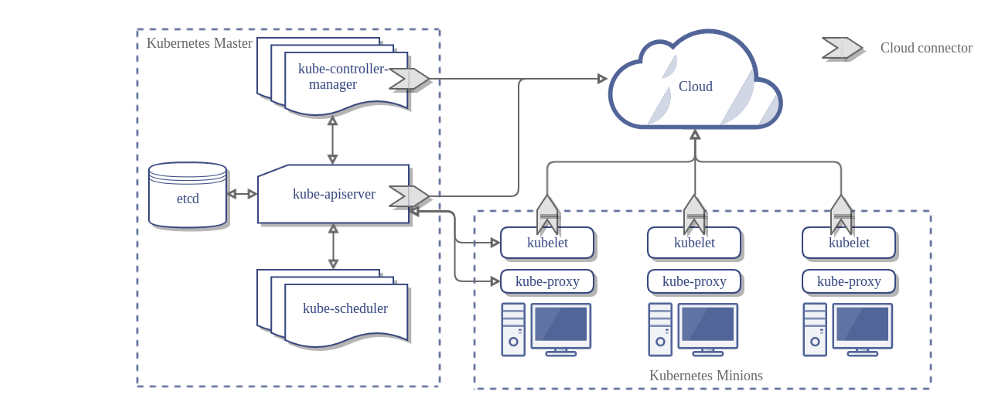
apiserver 负责接收 k8s 所有请求,所有增删改查和监听操作都交给 apiserver 处理后再提交给 etcd 存储。
etcd 是一个分布式的键值存储系统。存储了 k8s 的关键配置和用户配置,仅 apiserver 才具备读写权限,其他组件必须通过 apiserver 的接口才能读写数据。其内部使用 Raft 协议。
scheduler 是负责资源调度的进程,根据调度算法为新创建的 pod 选择一个合适的 worker 节点。
controller-manager 是 k8s 集群里所有资源对象的自动化控制中心,通过 apiserver 监视集群的状态,确保集群的当前状态是否符合期望。
kubelet 是从节点的监视器,与 master 节点的通讯器。与 apiserver 通信查看分配给该节点的应用程序容器,负责启动 pod 运行分配到节点的应用程序。
kube-proxy 能够让容器跨集群的各个节点相互通信。kube-proxy 处理所有网络问题,例如如何将流量转发到适当的 pod 上,实现负载均衡。
所有的组件都通过 apiserver 交互,将集群的状态存储在 etcd 中。多种组件(通过 apiserver)写入 etcd,以对集群进行更改,集群上的节点(通过 apiserver)监听 etcd,以查看其应该运行的 pod。
k8s 工作流程:
- 用户通过客户端发送创建 pod 的请求到 master 节点上的 apiserver
- apiserver 会先把相关的请求信息写入到 etcd 中,再找 controller-manager 根据预设的资源模板创建 pod 清单
- 然后 controller-manager 会通过 apiserver 去找 scheduler 为新创建的 pod 选择最适合的 worker 节点
- scheduler 会通过调度算法的预选策略和优选策略筛选出最适合的 worker 节点
- 然后再通过 apiserver 找到对应的 worker 节点上的 kubelet 去创建和管理 pod
- kubelet 会直接跟容器引擎交互来管理容器的生命周期
- 用户通过创建承载在 kube-proxy 上的 service 资源,写入相关的网络规则,实现对 pod 的服务发现和负载均衡