「论」 FastFabric: Scaling Hyperledger Fabric to 20,000 Transactions per Second
本文最后更新于:1 年前
本文重新构建了 Hyperledger Fabric,减少事务排序和验证期间的计算和 I/O 开销,从而大大提高吞吐量,将交易吞吐量从每秒 3000 笔提高到 20000 笔。值得注意的是,本文的优化是即插即用的,不需要对 Fabric 进行任何接口更改。
I. INTRODUCTION
相比公链,许可链通常将共识和交易验证委托给选定的一组节点,从而减轻共识算法的负担。但即使在这种情况下,共识仍然是一个瓶颈。
本文中仔细研究了 Hyperledger Fabric 1.2 的设计,基于常见的系统设计技术设计并实现了几种体系结构优化,这些技术将系统 tps 提高了近 7 倍,从每秒 3000 提高到 20000,同时降低了块延迟。具体贡献如下:
- Separating metadata from data:Fabric 中的共识层接收整个交易作为输入,但只需要 ID 来决定交易顺序。我们重新设计了 Fabric 的排序服务,使其仅使用交易 ID,从而大大提高了吞吐量。
- Parallelism and caching:交易验证的某些方面可以并行化,而其他地方可以从缓存交易数据中获益。我们重新设计了 Fabric 的交易验证服务,在 committers 中积极缓存未组装的块,同时并行化尽可能多的验证步骤,包括背书策略验证和语法验证。
- Exploiting the memory hierarchy for fast data access on the critical path:Fabric 保持全局状态的键值存储可以被轻量级的内存数据结构所取代,这些结构缺乏持久性保证,可以通过区块链本身来弥补。我们围绕轻量级哈希表重新设计了 Fabric 的数据管理层,该哈希表可以更快地访问关键交易验证路径上的数据,将不可变块的存储推迟到写优化的存储集群。
- Resource separation:提交者和背书者节点争夺资源。我们介绍了一种将这些角色转移到单独硬件的体系结构。
II. FABRIC ARCHITECTURE
A. Node types
客户端发起交易,即对区块链的读取和写入,这些交易被发送到 Fabric 节点。节点要么是 peers,要么是 orderers;一些 peers 也是 endorsers。所有 peers 将区块提交到区块链的本地副本,并将相应的更改应用于维护当前世界状态快照的 state database。背书节点可以根据链码中的业务规则来证明交易是有效的。排序节点只负责决定交易顺序,而不验证正确性或有效性。
B. Transaction flow
- 客户将其交易发送给一定数量的背书节点。
- 每个背书节点在沙盒中执行事务,并计算相应的读写集以及访问的每个键值的版本号。每个背书节点还使用业务规则来验证交易的正确性。
- 客户端等待足够数量的背书,然后将这些响应发送给排序节点。
- 排序节点首先对传入交易的顺序达成共识,然后将消息队列划分为块。
- 块被传递给对等节点,然后由对等节点验证并提交它们。
C. Implementation details
Orderer
客户端收到背书节点响应后,会创建一个包含 header 和 payload 的交易提案,header 包含交易 ID 和通道 ID,payload 包含读写集和其对应的版本号,以及背书节点的签名集。客户端对交易提案签名,并发送给排序服务。
排序服务的两个目标:(a) 对交易排序达成共识,(b) 出块并发送给节点。本文中 Fabric 使用基于 ZooKeeper 的 Apache Kafka 来实现崩溃容错共识。
当排序节点收到交易提案时,它会检查客户端是否有权提交交易。如果通过,排序节点将交易提案发布到 Kafka cluster,其中每个 Fabric 通道都映射到一个 Kafka topic,以创建相应的不可变的交易序列顺序。然后,每个排序节点根据每个块允许的最大交易数或超时时间,将从 Kafka 接收的交易组装成块,签名并使用 gRPC 将块传递给节点。
Peer
在接收到来自排序服务的消息时,对等节点首先对块的头和元数据进行解码,并检查其语法结构,然后验证创建此块的排序节点的签名。未通过这些测试的块将立即被丢弃。初始验证之后,区块被加入队列,从而保证其被添加到区块链中。之后块会依次经过两个验证步骤和一个提交步骤。
在第一个验证步骤中,对块中的所有交易进行解码,检查它们的语法并验证它们的背书集。未通过的交易被标记为无效,但保留在块中。这一步使得恶意交易被排除。
在第二个验证步骤中,节点确保有效交易间的相互作用不会导致无效的世界状态。回想一下,每一笔交易都携带一组需要从世界状态数据库读取的键(读集)和一组将写入数据库的键和值(写集),以及背书节点记录的版本号。在第二个验证步骤中,交易读写集中的每个键都必须具有相同的版本号。这样可以防止双重支付。
在最后一步中,对等节点将块写入文件系统,该块现在包含交易的验证标志。根据应用程序的配置,键值(即世界状态)将持久化在 LevelDB 或 CouchDB 中。每个块及其交易的索引都存储在 LevelDB 中,以加快数据访问速度。
III. DESIGN
A. Preliminaries
使用拜占庭容错(BFT)共识算法是 HyperLedger 中的一个关键性能瓶颈。在我们的工作中,我们选择跳过这一明显的瓶颈,原因有三:
在许可区块链中使用 BFT 协议并不像在无许可的系统中那么重要,因为所有参与者都是已知的,并被激励以诚实的方式保持系统运行。
BFT 共识正在被广泛研究,我们预计在未来一两年内会出现更高吞吐量的解决方案。
在实践中,Fabric 1.2 不使用 BFT 共识协议,而是依赖于 Kafka 进行交易排序,如前所述。
B. Orderer improvement I: Separate transaction header from payload
在 Fabric 1.2 中,使用 Apache Kafka 的排序节点将整个交易发送给 Kafka 进行排序。交易的长度可能是几千字节,这会导致高通信开销,从而影响整体性能。然而,在交易顺序上获得共识只需要交易 ID,因此我们可以通过只向 Kafka 发送交易 ID 来显著提高排序节点的吞吐量。具体来说,在从客户端接收到交易时,排序节点从 header 中提取交易 ID,并将该 ID 发布到 Kafka 集群。排序节点将相应的 payload 单独存储在本地数据结构中,当从 Kafka 收到 ID 时,交易将重新组装。
C. Orderer improvement II: Message pipelining
在 Fabric 1.2 中,排序服务逐个处理来自客户端的传入交易。当交易到达时,识别其对应的通道,根据一组规则检查其有效性,最后将其转发到共识系统(Kafka),然后才能处理下一笔交易。我们实现了一种流水线机制,可以同时处理多个传入交易,即使它们来自使用相同 gRPC 连接的同一客户端。为此,我们维护了一个并行处理传入请求的线程池,每个传入请求有一个线程。线程调用 Kafka API 来发布交易 ID,并在成功时向客户端发送响应。
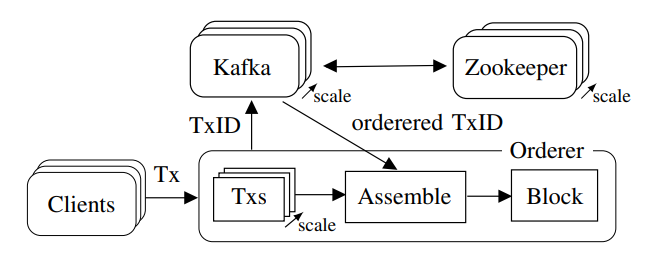
D. Peer tasks
在接收到区块时,Fabric 节点按顺序执行以下任务:
- 验证接收到的消息的合法性
- 验证区块中每个交易的区块头和每个背书签名
- 验证交易的读写集
- 在 LevelDB 或 CouchDB 中更新世界状态
- 将区块链日志存储在文件系统中,并在 LevelDB 中提供相应的索引
我们的目标是在交易流的关键路径上最大限度地提高吞吐量。为此,我们进行了调用图分析,以确定性能瓶颈。首先,交易读写集的验证需要快速访问世界状态。因此,我们可以通过使用内存中的哈希表而不是数据库来加快这一过程。其次,交易流不需要区块链日志,因此我们可以推迟到交易流结束时将其存储到专用存储和数据分析服务器。第三,如果节点是背书节点,则需要处理新的交易提案。然而,提交者和背书者的角色是不同的,因此可以为每个任务分配不同的物理硬件。第四,传入的块和交易必须在节点进行验证和解析。最重要的是,通过交易写集对状态更改的验证必须按顺序进行,这会阻止所有其他任务。因此,尽可能加快这项操作是很重要的。最后,通过缓存块的 Protocol Buffers 解码的结果,可以获得显著的性能增益。
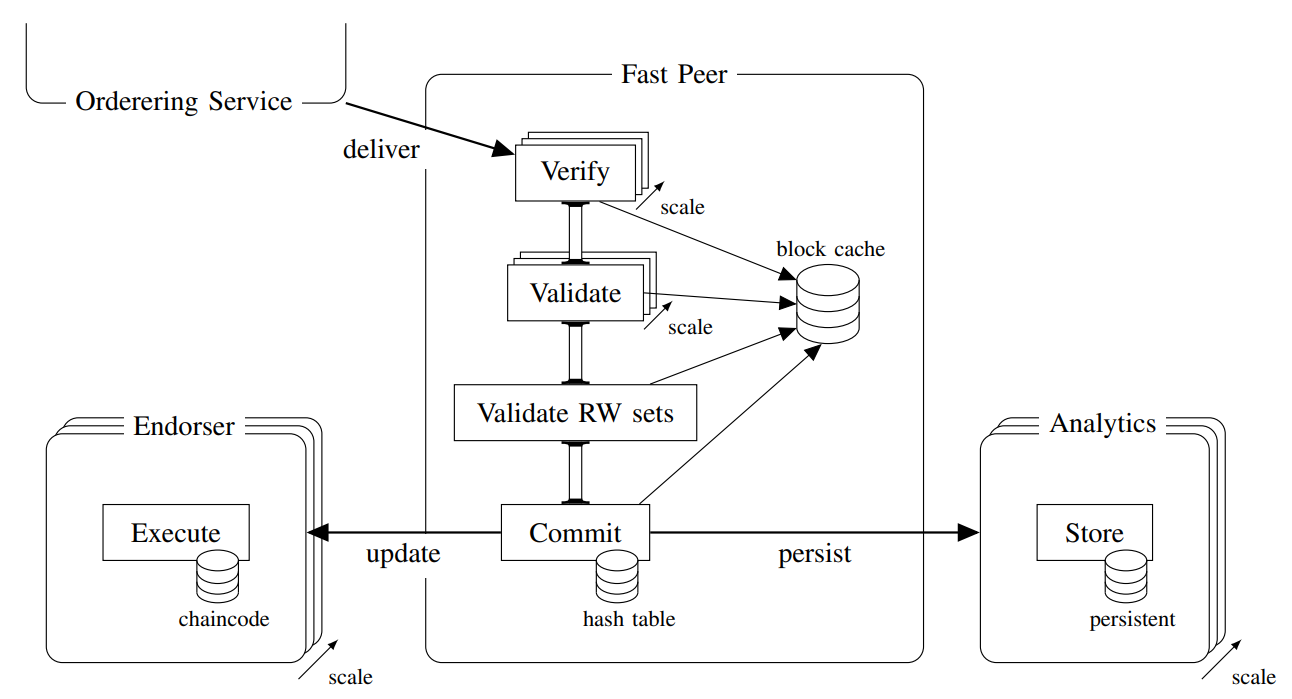
E. Peer improvement I: Replacing the world state database with a hash table
我们认为,对于常见的情况,例如跟踪钱包或账本上的资产,世界状态相对较小。即使需要存储数十亿个键值,大多数服务器也可以很容易地将它们保存在内存中。因此,我们建议使用内存中的哈希表来存储世界状态,而不是 LevelDB/CouchDB。这消除了在更新世界状态时对硬盘的访问,还消除了由于区块链本身的冗余保证而不必要的昂贵的数据库系统保证(即,ACID 属性),进一步提高了性能。当然,由于使用易失性存储器,这种替换易受节点故障的影响,因此必须通过稳定存储来增强内存中的哈希表。
F. Peer improvement II: Store blocks using a peer cluster
根据定义,区块是不可变的。这使它们非常适合追加式数据存储。通过将数据存储与节点的其余任务分离,我们可以设想许多类型的数据存储用于区块和世界状态备份,包括单个服务器将区块和世界状态备份存储在其文件系统中,就像 Fabric 目前所做的那样;也可以使用数据库或键值存储,例如 LevelDB 或 CouchDB。为了最大限度地扩展,我们建议使用分布式存储集群。此解决方案中每个存储服务器仅包含链的一部分,可以使用分布式数据处理工具,如 Hadoop MapReduce 或 Spark5。
G. Peer improvement III: Separate commitment and endorsement
在 Fabric 1.2 中,背书节点也负责提交区块。背书是一个昂贵的操作,提交也是如此。虽然在背书节点集群上的并发事务处理会提高性能,但在每个新节点上重复提交的额外工作实际上抵消了这些好处。因此,我们建议拆分这些角色。
在我们的设计中,提交节点执行验证流程,然后将已验证的区块发送到一个背书节点集群,这些节点仅将更改应用于其世界状态而不进行验证。这一步骤允许我们释放节点上的资源。这样的背书节点集群可以通过只将节点的背书角色分离到专用硬件上以满足需求。该集群中的服务器并不相当于 Fabric 1.2 中完整的背书节点。
H. Peer improvement IV: Parallelize validation
区块和交易头验证都包括检查发送方的权限、背书策略和语法验证,具有高度可并行性。我们通过引入完整的验证流水线来扩展 Fabric 1.2 的并发性能。
具体而言,对于每个传入的区块,分配一个 go-routine 来引导其通过区块验证阶段。随后,这些 go-routines 中的每一个都利用 Fabric 1.2 中已经存在的用于交易验证的 go-routine 池。因此,在任何给定时间,多个区块及其交易都可以并行地进行有效性检查。最后,所有读写集合按正确顺序由单个 go-routine 顺序验证。这使我们能够充分利用多核服务器 CPU 的潜力。
I. Peer improvement V: Cache unmarshaled blocks
Fabric 在网络节点之间使用 gRPC 进行通信。为了准备数据进行传输,使用 Protocol Buffers 进行序列化。为了能够处理应用程序和软件随着时间的推移进行的升级,Fabric 的区块结构高度分层,每个层都分别进行序列化和反序列化。这导致大量内存被分配用于将字节数组转换为数据结构。此外,Fabric 1.2 不会在缓存中存储先前解析的数据,因此每当需要数据时就必须重新进行此操作。
为了优化这个问题,我们计划用一个临时的缓存来存放解析的数据。验证流水线中区块被存储在缓存中,并在需要时按块编号检索。一旦块的任何部分被解析,它就与块一起存储以供重用。我们将其实现为一个循环缓冲区,大小与验证流水线相同。每当提交一个块时,就可以接受一个新块到管道中,并自动覆盖已提交块的缓存位置。由于在提交后不需要缓存,并且保证新块仅在旧块离开管道后才到达,因此这是一个安全的操作。解组仅向缓存添加数据,它从不更改数据,所以在验证流水线中可以为所有 go-routines 提供无锁访问。在最坏的情况下,多个 go-routines 尝试访问相同的(但尚未解析的)数据,并且所有 go-routines 并行执行解析操作,缓存的最后写入获胜。这是没有问题的,因为大家执行结果都是相同的。
IV. RESULTS
实验配置略。
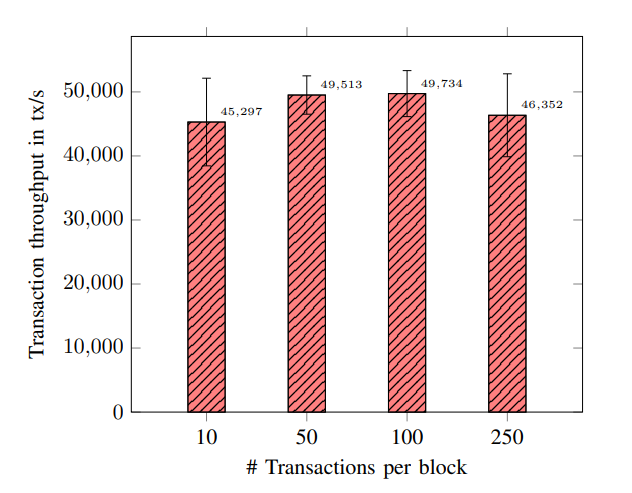
A. Block transfer via gRPC
我们预先创建了包含不同数量交易的有效块,通过 Fabric gRPC 接口将它们从一个 orderer 发送到 peer,然后立即丢弃它们。
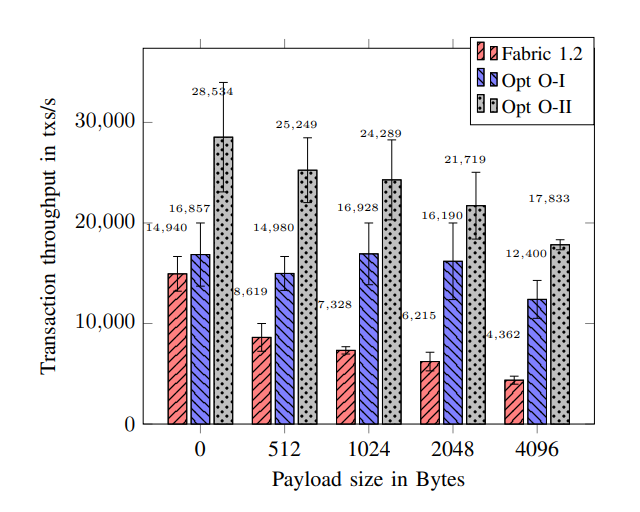
B. Orderer throughput as a function of message size
在这个实验中,我们设置了多个客户端,这些客户端向排序节点发送交易,并监控发送 100000 个交易所需的时间。我们评估在 Fabric 1.2 中排序交易的速率,并将其与我们的改进进行比较:
- Opt O-I: only Transaction ID is published to Kafka (Section III-B)
- Opt O-II: parallelized incoming transaction proposals from clients (Section III-C)
C. Peer experiments
本节在单独节点上进行测试。我们准备好块,并将它们发送给节点,就像我们在第 IV-A 节的 gRPC 实验中所做的那样。然后,节点完全验证并提交块。
- Opt P-I: LevelDB replaced by an in-memory hash table
- Opt P-II: Validation and commitment completely parallelized; block storage and endorsement offloaded to a separate storage server via remote gRPC call
- Opt P-III: All unmarshaled data cached and accessible to the entire validation/commitment pipeline
- Experiments with fixed block sizes:单次运行 100000 个交易的验证和提交,重复 1000 次,每个区块包含 100 笔交易。
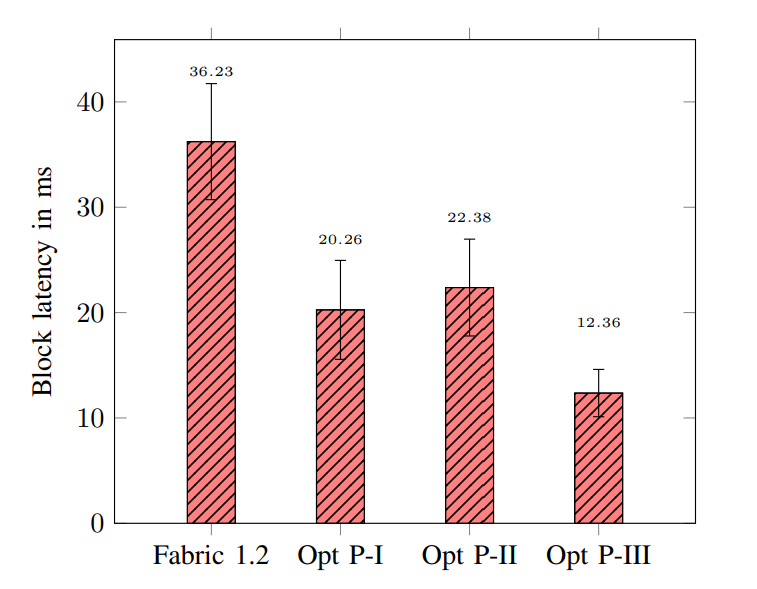
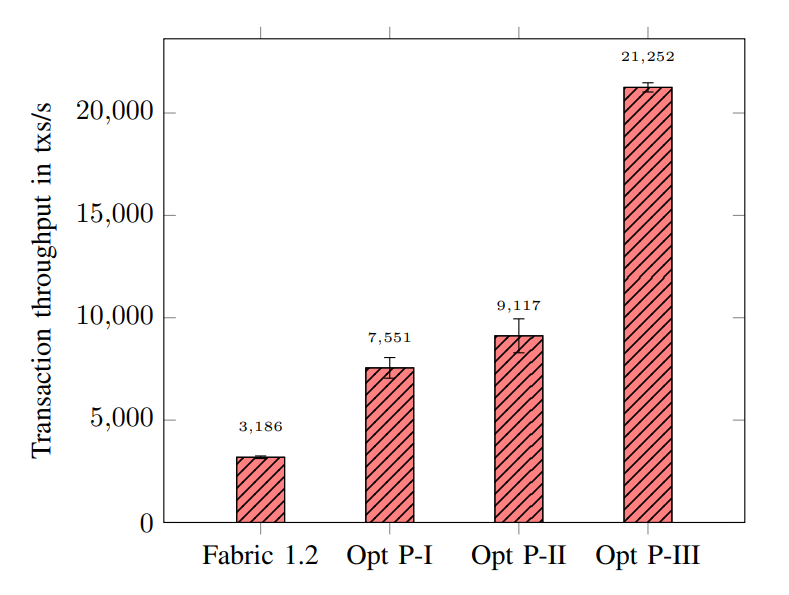
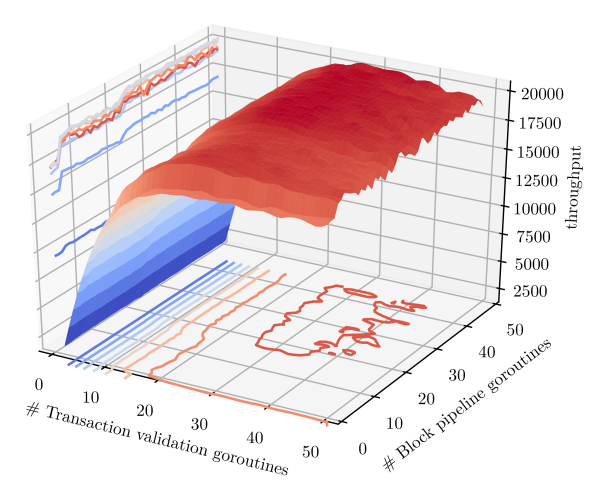
- Parameter sensitivity:测试改变两个参数对并行化性能的影响。
- 在验证流程中并行引导块的 go-routines 的数量
- 并行验证交易的 go-routines 的数量
我们使用 semaphores 控制系统中 go-routines 的数量,同时允许多个块同时进入验证管道。这使我们能够通过两个独立的 go-routine pools 来控制块头验证和交易验证的并行度。
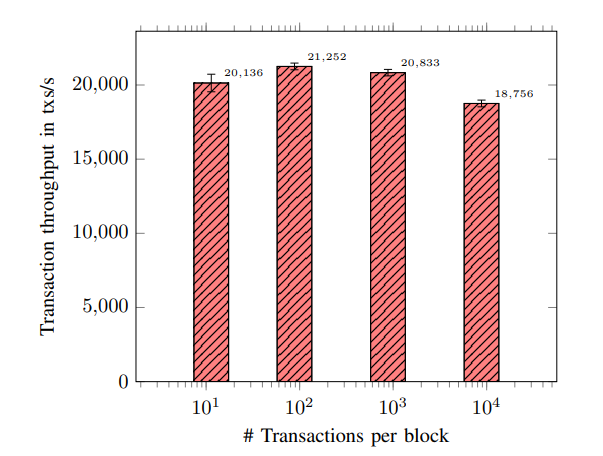
配置 24 ± 2 交易验证 go-routines,验证通道中有 30 ± 3 个区块,测试区块大小的影响。
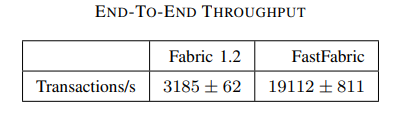
D. End-to-end throughput
我们现在讨论通过组合所有优化实现的端到端吞吐量。O-II 与 P-III,与 Fabric 1.2 的测量结果对比。
V. RELATED WORK
略
VI. CONCLUSIONS
略