「论」 Performance Benchmarking and Optimizing Hyperledger Fabric Blockchain Platform
本文最后更新于:1 年前
这篇文章发现了 Fabric v1.0 的三个主要性能瓶颈:(1) 背书策略验证;(2) 块中交易的顺序策略验证;(3) CouchDB 的状态验证和提交。同时对上述问题进行了简单的优化,如加密组件中用于背书策略验证的主动缓存、并行背书策略验证、增强并测量了 CouchDB 的现有批量读/写优化的效果。
I. INTRODUCTION
与公链相比,许可链每个参与者的身份都是已知的,并且经过加密身份验证,这样区块链就可以存储谁进行了哪些交易。这样的网络可以内置访问控制机制,以限制谁可以 (a) 读取和附加账本数据,(b) 发布交易,(c) 管理区块链网络的参与者。所以非常适用于要求身份验证的企业级应用程序。
Fabric 提供了许多可配置的参数(block size,endorsement policy,channels,state database),因此,建立高效区块链网络的主要挑战之一就是为这些参数找到合适的值。
本文的三个主要贡献:
- 我们进行了 1000 多次实验,通过改变五个主要参数的赋值,对 Fabric 平台进行了全面的测试,并且提供了六条关于配置这些参数以获得最大性能的指导方针。
- 我们确定了三个主要的性能瓶颈:(i) 加密操作,(ii) 区块中的交易串行验证,(iii) 对 CouchDB 的多个 REST API 调用。
- 进行三种简单优化,在单通道环境下将整体性能提高 16 倍。代码见 https://github.com/thakkarparth007/fabric。
II. BACKGROUND: HYPERLEDGER FABRIC ARCHITECTURE & CONFIGURATION PARAMETERS
A. Key Components in Fabric
Peer:对等节点执行实现用户智能合约的链码,并且在文件系统中维护账本。节点被进一本分为背书节点(endorsing peer,具有链码逻辑)和提交节点(committing peer,没有链码逻辑)。对等节点在键值存储中将当前状态维护为 StateDB,以便链码可以使用数据库查询语言查询或修改状态。
Endorsement Policies:指定一组节点来模拟执行交易,并对执行结果签名背书。
System chaincodes:系统链码与普通用户链码具有相同的程序设计模型,并内置于对等节点可执行文件中,这与用户链码不同。
- LSCC(life cycle system chaincode)用于安装/实例化/更新链码;
- ESCC(endorsement system chaincode)通过对响应进行数字签名来背书交易;
- VSCC(validation system chaincode)根据背书策略验证交易的背书签名集;
- CSCC(configuration system chaincode)管理通道配置。
Channel:Fabric 引入通道的概念————两个或多个对等节点之间通信的“专用”子网,以提供一定程度的隔离。
Ordering Service:排序节点(OSN)参与共识协议并出块,然后通过 gossip 协议传递给对等节点。区块结构如下图所示:

OSNs 将交易发布到 kafka 并利用其记录的有序和不可变性来生成唯一的有序区块。
- Client:客户端应用负责将交易提案组装成上图的形式,然后将交易提案同时提交给一个或多个对等节点,以收集带有背书的提案响应,满足背书政策后再将其广播给排序者。
B. Transaction Flow in Hyperledger Fabric
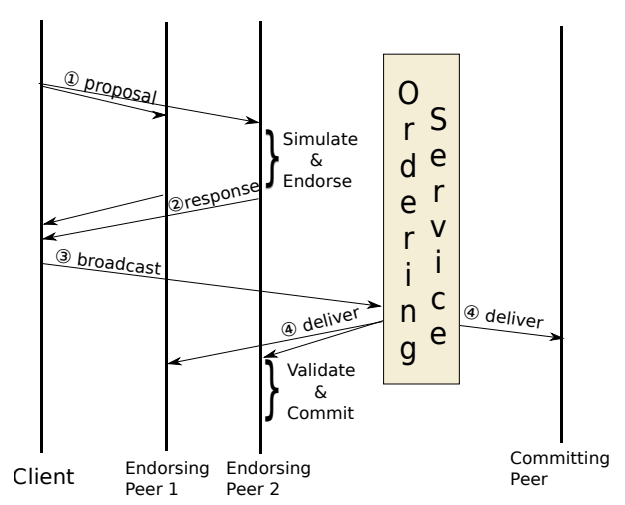
Endorsement Phase
客户端根据背书政策发送交易。背书节点收到客户端发来的交易,首先验证提交者有调用交易的权限;其次执行链码并产生 response value,read-set 和 write-set,读集读取当前的区块链状态,写集仅修改一个私有的工作区,即未提交到账本;然后背书节点调用 ESCC 签署背书并回复客户端;最后客户端验证提案响应。Ordering Phase
客户端将交易(read-write sets,endorsing peer signatures,Channel ID)包装好发给排序节点。排序服务并不检查交易内容,只按照通道分别排序并出块。给块签名后使用 gossip 传递给节点。Validation Phase
所有节点都会收到区块,首先检查排序者的签名,有效块被解码,并且块中的所有交易在执行 MVCC 验证之前首先经过 VSCC 验证。- VSCC Validation:根据为链码指定的背书策略评估交易中的背书。如果不满足背书策略,则该交易被标记为无效。
- MVCC Validation:Multi-Version Concurrency Control 顺序检查有效交易(VSCC 标记)在背书阶段读取键值的版本与提交时本地账本中的当前状态是否相同,类似于为并发控制所做的读写冲突检查。
Ledger Update Phase
StateDB 使用有效事务(MVCC 验证所标记)的写集进行更新。
C. Configuration Parameters
- Block Size
- Endorsement Policy
- Channel
- Resource Allocation
- Ledger Database
III. PROBLEM STATEMENT
本文工作的两个主要目标:
- Performance Benchmarking.
- Optimization.
IV. EXPERIMENTAL METHODOLOGY
两个性能指标:Throughput(交易提交到账本的速率)和 Latency(从客户端发送提案到交易上链的时间)。
延时主要由以下部分组成:
- Endorsement latency:客户端收集提案响应以及背书所花的时间。
- Broadcast latency:客户端传播交易到排序节点和排序节点验证客户端的时间。
- Commit latency:节点验证和提交交易的时间。
- Ordering latency:交易排序所用的时间(本文未讨论)。
本文又定义了三个区块级别的延时:
- VSCC validation latency:验证一个区块所有交易背书的签名集的时间。
- MVCC validation latency:采用多版本并发控制验证一个区块所有交易的时间。
- Ledger update latency:根据一个区块有效交易的写集改变数据库状态的时间。
使用 load generator 生成交易,fetch-block 测试。
A. Setup and Workloads
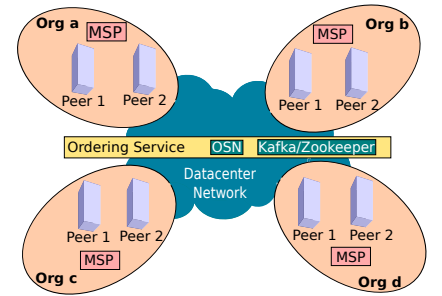
4 个组织,每个组织 2 个背书节点,1 个排序节点(硬件配置略)。
V. EXPERIMENTAL RESULTS
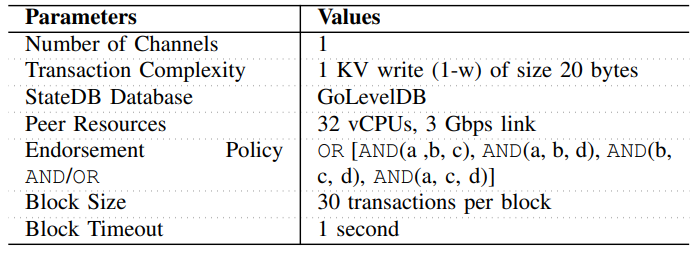
A. Impact of Transaction Arrival Rate and Block Size
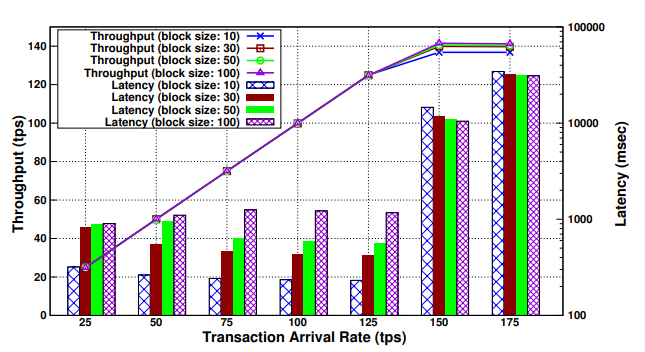
Observation 1:throughput 随交易到达率线性增长,直到 140 tps 左右饱和,在饱和点附近延时显著增长。这是因为验证阶段 VSCC 队列中等待的有序交易数量显著增长,影响了提交延迟。进一步提高交易到达率并不会影响背书延时和广播延时,仅影响提交延时,这是因为 VSCC 利用单个 vCPU,新的交易提案使用了对等节点上的其他 vCPU 进行模拟和背书。所以只有验证阶段会成为性能瓶颈。
Observation 2:交易到达率低于饱和点时,区块越大延时越高。原因是随着块大小的增加,排序服务的块创建时间增加,因此平均而言,交易在排序节点等待更长的时间。
Observation 3:交易到达率高于饱和点时,区块越大延时越低。这是因为验证和提交一个大小为 n 的块所花费的时间总是小于验证和提交 m 个大小为 n/m 的块所花的时间。
Observation 4:当区块大小低于某个阈值时,延迟随着到达速率的增加而减少;高于阈值时,延迟随着到达率的增加而增加。对于较小的区块和较高的到达速率,块的创建速度更快,减少交易在排序节点等待的时间。对于较大的区块,随着到达率的增加,块中的事务数量增加,验证和提交阶段所花费的时间也增加了。
Observation 5:即使在 throughput 达到峰值时,资源利用率也非常低。原因是在块的 VSCC 验证阶段执行的 CPU 密集型任务一次只处理一个事务。由于这种串行执行,只使用了一个 vCPU。
Guideline 1:当交易到达率预计低于饱和点时,为了实现应用程序更低的延迟,始终使用更小的块。在这种情况下,吞吐量将与到达速率相匹配。
Guideline 2:当交易到达率预计较高时,为了实现更高的吞吐量和更低的延迟,使用更大的块。
Action Item 1:CPU 资源利用不足,潜在的优化是在 VSCC 验证阶段一次处理多个事务。
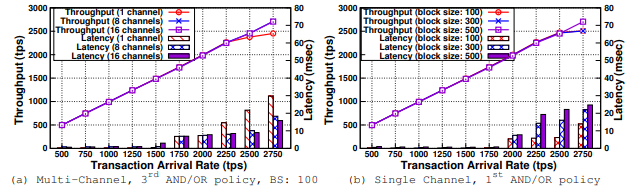
B. Impact of Endorsement Policy
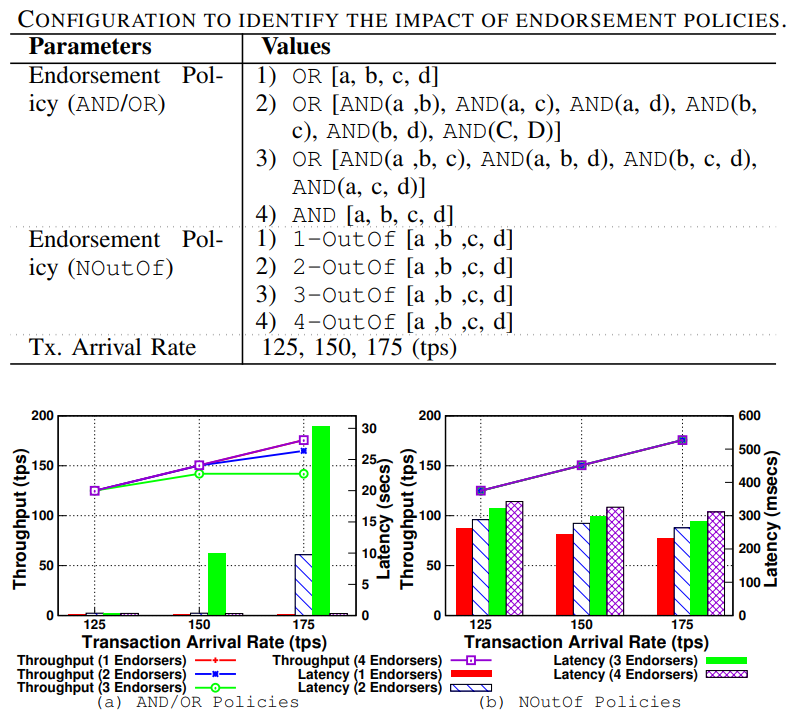
研究不同的背书策略对性能影响,其中 a b c d 是四个不同的组织。
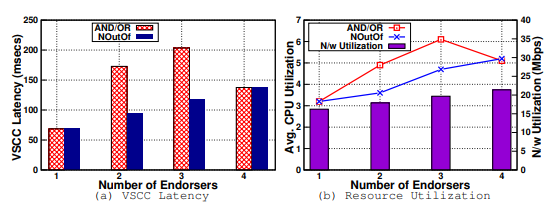
Observation 6:多个子策略和多个加密签名验证的组合影响了性能(CPU 利用率和 VSCC 延迟)。1 和 4 背书策略没有子策略,2 和 3 AND/OR 策略实现的吞吐量分别比其他策略低 7% 和 20%。
Guideline 3:使用较少数量的子策略和签名来制定策略实现更高性能。
Action Item 2:由于加密操作是 CPU 密集型的,我们可以通过维护反序列化身份及其 MSP 信息的缓存来避免某些重复操作。身份是长期存在的,并且维护单独的证书吊销列表(CRL)。
C. Impact of Channels and Resource Allocation
我们将不同信道数量的到达率分为两类:non-overloaded(延迟在 [0.4-1s])和 overloaded(延迟范围 [30-40s])。
Number of Channels: 1, 2, 4, 8, 16.
Tx. Arrival Rate: 125 to 250 tps with a step of 25.
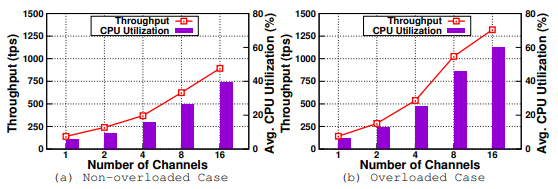
- Observation 7:随着通道数量的增加,吞吐量增加,延迟减少,CPU等资源利用率也有所提高。这是因为每个通道都独立于其他通道,并维护自己的区块链。因此,多个块(每个通道一个)的验证阶段和最终账本更新并行执行,这增加了 CPU 利用率,从而提高了吞吐量。

- Observation 8:在中等负载下,当分配的 vCPU 数量小于通道数时,性能下降。由于 CPU 资源的大量竞争,平均背书和提交延迟都呈爆炸式增长(分别从 37ms 到 21s 和 640ms 到 49s)。
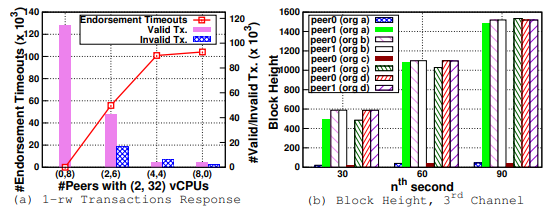
Observation 9:在中等负载下,即使分配给 8 个对等点中的 2 个对等点的 vCPU 数量小于通道数,性能也会下降。原因有两个,一是来自功能较弱的对等节点的背书请求超时,二是专门针对读写事务的 MVCC 冲突。
Guideline 4:为了实现更高的吞吐量和更低的延迟,最好为每个通道分配至少一个 vCPU。为了优化 vCPU 分配,我们需要确定每个通道的预期负载,并相应地分配足够的 vCPU。
Guideline 5:为了实现更高的吞吐量和更低的延迟,最好避免异构对等节点,因为系统性能将由功能较弱的对等节点决定。
Action Item 3:可以改进通道内和通道间的交易处理,以更好地利用额外的 CPU 能力。
D. Impact of Ledger Database
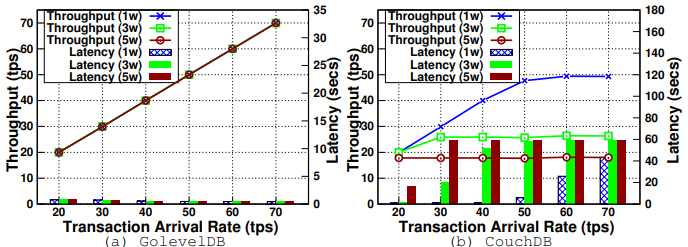
- Observation 10:以 GoLevelDB 作为 Fabric 的状态数据库,事务吞吐量是 CouchDB 的 3 倍。CouchDB 和 GoLevelDB 之间存在显著性能差异的原因是,后者是一个对等节点进程的嵌入式数据库,而前者是通过安全的 HTTP 使用 REST APIs 访问的。因此 CouchDB 的背书延迟、VSCC 延迟、MVCC 延迟和账本更新延迟更高。

Observation 11:对于 CouchDB,背书延迟和账本更新延迟随着每笔交易写入次数的增加而增加。
Observation 12:只有随着每个交易的读操作次数的增加,MVCC 延迟才会增加。
Guideline 6:对于状态数据库来说,GoLevelDB 是一个性能更好的选项。如果对只读事务的富查询支持很重要,那么 CouchDB 是一个更好的选择。
Action Item 4:CouchDB 支持批量读写操作,而不需要额外的事务语义。可以使用批量操作缩短锁的持续时间并提高性能。
Action Item 5:在没有快照隔离级别的情况下,使用 GoLevelDB 和 CouchDB 等数据库会导致背书和账本更新阶段的整个数据库锁定。因此,我们未来的工作是研究如何移除锁或使用支持快照隔离的数据库,如 PostgreSQL。
E. Scalability and Fault Tolerant
在 Fabric 中,可扩展性可以根据通道数量、加入通道的组织数量以及每个组织的对等节点数量来衡量。从资源消耗的角度来看,背书策略的复杂性控制着网络的可扩展性。即使有大量的组织或节点,如果背书策略只需要少数组织签名,那么性能也不会受到影响。
节点故障在分布式系统中很常见,因此研究 Fabric 的容错能力很重要。在我们早期的研究中,我们观察到节点故障不会影响性能(在非过载情况下),因为客户端可以从其他可用节点收集背书。在负载较高的情况下,节点在故障后重新加入,并由于丢失块而同步账本,这有很大的延迟。这是因为尽管重新加入的节点处的块处理速率处于峰值,但是其他节点继续以相同的峰值处理速率添加新块。
VI. OPTIMIZATIONS STUDIED
三个简单优化方案和它们结合起来的效果。
A. MSP Cache
由于加密操作非常占用 CPU,在本节中,我们研究了在加密模块中的以下两个操作中使用缓存的效率:
- 身份的反序列化
- 组织 MSP 的身份验证
为了避免每次都对序列化的身份标识进行反序列化,我们使用以序列化形式为键的哈希映射来缓存反序列化的身份。类似地,为了避免每次使用多个 MSP 验证一个身份,我们使用了一个哈希表,其中身份作为键,值是该身份所属的相应 MSP。
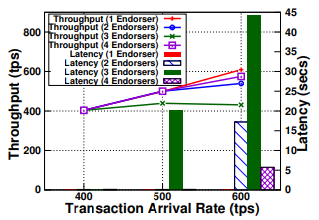
与普通对等节点相比,由于 MSP 缓存,吞吐量平均增加了 3 倍。
B. Parallel VSCC Validation of a Block
并行验证多个交易的背书,以利用闲置的 CPU 并提高整体性能。为了实现这一点,我们在对等节点启动时为每个通道创建了可配置数量的工作线程。每个工作线程根据其背书策略验证一个交易的背书签名集。
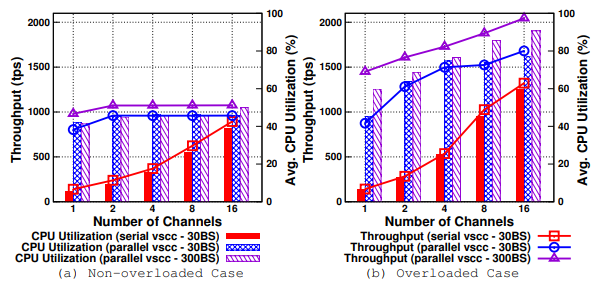
对于每个通道,我们分配了与块大小相等的工作线程。在一个通道的非过载情况下,对于 30 的块大小,吞吐量从 130 tps 提升到 800 tps(提高了6.3倍),对于 300 的块大小提升到 980 tps(7.5倍)。块内交易的并行 VSCC 验证显著提高了单个通道的性能。但是随着通道数量的增加,改善的百分比下降。这是因为默认情况下,多个通道会导致块(而不是交易)的并行验证,因此只有少量可用的 vCPU 可用于并行 VSCC。
C. Bulk Read/Write During MVCC Validation & Commit
在使用 CouchDB 作为状态数据库进行 MVCC 验证时,对于块中的每个交易读集中的每个键,使用安全的 HTTPS 协议进行 GET REST API 调用来检索最后提交的版本号。在提交阶段,对于块中的每个有效交易写集中的每个键,使用 GET REST API 调用来检索修订号。最后,对于写集中的每个条目,使用 PUT REST API 调用来提交记录。由于这些多个 REST API 调用,性能显著下降。
为了减少 REST API 调用的数量,CouchDB 建议使用批量操作。因此,我们使用 Fabric 中现有的 BatchRetrieval API,通过每个块的单个 GET REST API 调用,将多个键的版本和修订号批量加载到缓存中。为了增强账本更新过程,我们使用 BatchUpdate API 来提交一批记录,每个块调用一个 PUT REST API。此外,我们在 VSCC 中引入了一个缓存,以减少对 CouchDB 的调用,从而获得每个交易的背书策略。

要与上文非批量读写进行比较,对于单次写入的事务,性能从 50 tps 显著提高到 115 tps(2.3 倍)。对于多次写入(3-w 和 5-w),吞吐量从 26 tps 增加到 100 tps(3-w 为 3.8倍),从 18 tps 提高到 90 tps(5-w 为 5 倍)。我们注意到读写事务也有类似的改进。
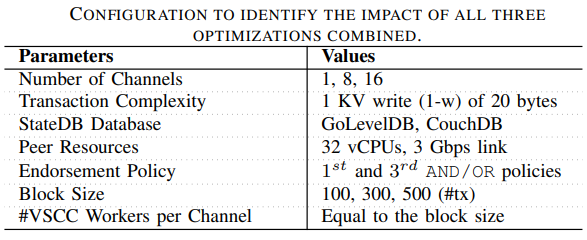
D. Combinations of Optimizations

VII. RELATED WORK
略
VIII. CONCLUSION & FUTURE WORK
略
IX. ACKNOWLEDGEMENTS
略