「论」 Blurring the Lines between Blockchains and Database Systems: the Case of Hyperledger Fabric
本文最后更新于:1 年前
区块链系统面临的许多挑战都是基本的交易管理问题,这在很大程度上与传统数据库系统一样。这些相似之处对于模糊了区块链系统和经典数据库系统之间界限的系统来说尤其明显,比如 Hyperledger Fabric。这就引出了两个问题:(1)Fabric 这样的系统和经典的分布式数据库之间存在哪些概念上的相似性和差异?(2)是否可以通过采用数据库技术提高 Fabric 的性能并进一步模糊这两种类型系统之间的界限?为了解决这些问题,我们首先从数据库研究的角度探讨 Fabric,然后通过将数据库概念转换到 Fabric 来解决这些问题,即事务重新排序和早期事务中止。我们的改进版本 Fabric++ 将成功交易的吞吐量提高了 12 倍,同时将平均延迟降低到几乎一半。
1 INTRODUCTION
经典的分布式数据库系统需要一组可信的参与者,但区块链系统能够处理一定数量的恶意节点。这个特性使得区块链系统可以应用于彼此并不完全信任的个体之间。在拜占庭容错方面,区块链系统比分布式数据库系统具有明显的优势,但就交易处理的其他方面而言,经典数据库系统都领先区块链系统几十年。
1.1 Catching up
Hyperledger Fabric 使用 simulate-order-validate-commit 模型,该模型在很大程度上受到数据库系统中乐观并发控制机制的影响:先并行模拟执行交易,排序后进行冲突检测,最后提交那些不冲突的交易。这个模型的优点很明显:并行执行交易,并因此具有可扩展性。
但是 Fabric 任然存在某种高度限制并发带来的增益的问题。这些问题可以在两个简单的实验中识别出来。

在第一个实验中,我们提交了有意义的资产转移交易流,并检测吞吐量,分为中止和成功交易。这个实验揭示了 Fabric 的一个严重问题:大量交易最终被中止。所有中止的原因都是序列化冲突,这是并发执行的负面影响。
如果我们想增加成功交易的数量,基本上有两种选择:
(a)增加系统的整体吞吐量;
(b)将原本会被 Fabric 中止的交易变为成功的交易。
第二个实验看可以看出(a)在 Fabric 中几乎不适用。我们提交了没有任何逻辑的空白交易。空白交易和有意义交易的总吞吐量基本相等。这表明系统的总体吞吐量并不是由交易处理的核心组件决定的,而是取决其他辅助因素:加密计算和网络开销。
1.2 Fabric++
所以选项(b)是关键,我们将通过一个众所周知的数据库技术来实现这一点:事务重新排序(transaction reordering)。
- 首先从概念的角度梳理 Hyperledger Fabric 1.2 版本的交易流程。
- 仔细查阅并发控制领域的相关工作,并讨论哪些技术与 Fabric 相关。
- 分析 Fabric 中交易流的基础上,我们详细讨论了它的弱点,并描述了如何利用数据库技术来克服这些弱点。
- 改进交易排序。系统默认将模拟后的交易任意排序,这导致一些不必要的序列化冲突。我们引入一种事务重新排序机制(transaction reordering mechanism)来改善这个问题。
- 提前中止交易。Fabric 在最后提交前才检测交易有效性,这使得系统完整的处理了很多本没有机会提交的交易。我们引入早期中止(early abort)的概念到流水线的各个阶段。这些改动显著扩展了 Fabric,我们将其称为 Fabric++。
- 在 Smallbank 基准测试和自定义工作负载下对 Fabric++ 的优化进行了实验评估。
2 HYPERLEDGER FABRIC
2.1 Architecture
Fabric 是一个许可区块链系统,这意味着网络的所有 peers 在任何时间都是已知的,peers 被分到 organization 中,在同一个组织中的 peers 都相互信任。每个 peer 都运行 Fabric 的本地实例。此实例包括分类账(ledger)的副本,其中包括有效事务和无效事务。每个 peer 还以状态数据库的形式包含当前状态(current state),该状态数据库表示分类账中所有有效交易应用到初始状态后的状态。此外还有一个名为 ordering service 的独立实例。
2.2 High-level Workflow
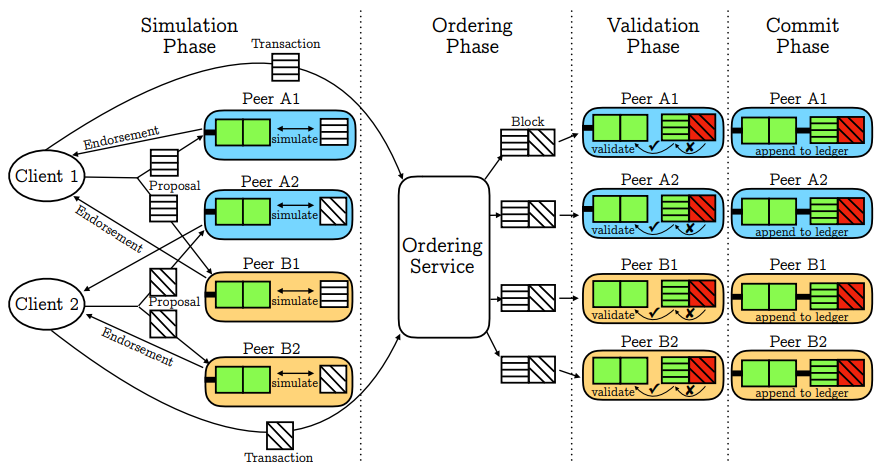
2.2.1 Simulation Phase.
背书节点根据本地当前状态并行模拟执行交易,结果并不用于更新当前状态。生成并返回读写集给客户端。
2.2.2 Ordering Phase.
按照交易到达的顺序排序。
2.2.3 Validation Phase.
先检查背书签名,再检查序列化冲突。
2.2.4 Commit Phase.
提交区块到本地帐本,并将有效交易的写集应用于当前状态。
3 RELATED WORK
尽管 Fabric 是一个并行事务处理系统,但它在四个方面与并行数据库系统不同:
Fabric 以块的粒度提交,而不是以单个交易的粒度提交。
Fabric 是一个分布式系统,其状态在网络上完全复制,交易在所有节点上运行。与此相反,并行数据库系统通常要么本地安装在单个节点上,要么在网络上对其状态进行分区,使得事务在网络的子集上操作。
Fabric 在多个节点上并行模拟单个交易以建立信任,对交易进行模拟的状态可能会因为跨节点而发生变化。在并行数据库系统中,情况要简单得多:一个事务只针对系统中存在的唯一状态执行一次。
Fabric 的性能在很大程度上取决于加密签名计算、网络通信和信任验证。相比之下,并行数据库系统的性能在很大程度上受到底层组件的影响,例如用于并发控制的锁定机制。
3.1 Class 1: Transaction Throughput
此节列举许多在数据库中增加吞吐量的技术,但是由第一章的实验可知并不适用于 Fabric。
3.2 Class 2: Transaction Abort & Success
此节列举了一些将中止交易转化为成功交易的研究,并认为这是 Fabric 性能提升的关键。
4 BLURRED LINES: FABRIC VS DISTRIBUTED DATABASE SYSTEMS
4.1 The Importance of Transaction Order
排序机制存在于任何具有事务语义的分布式数据库系统中,因此是将数据库技术转变为 Fabric 技术一个很好的候选者。由于 Fabric 的排序在交易执行之后,所以会影响产生冲突交易的数量。
最简单的排序方式是任意排序,比如按照交易到达的时间建立顺序,Fabric 就是采用的这种方式。如下图所示这种策略可能是有问题的:
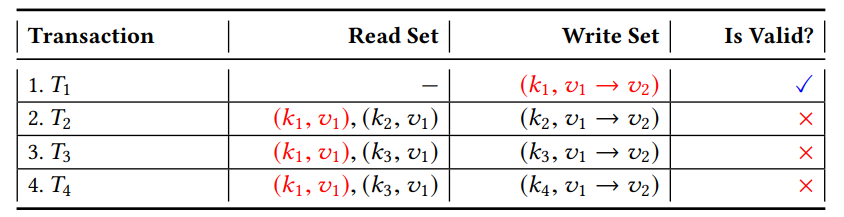
T1 将 k1 从版本 v1 更新到版本 v2。由于 T2、T3 和 T4 在其模拟过程中每个都读取版本 v1 中的 k1,因此它们将在验证阶段被标记为无效,客户必须重新提交相应的交易提案,从而进行新一轮的模拟、排序和验证。
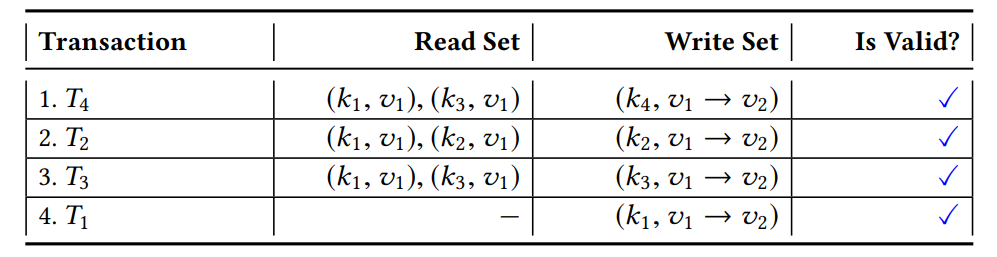
然而这四个交易其实存在无冲突排序,可以使它们都被标记为有效交易:
4.2 On the Lifetime of Transactions
根据 Fabric 验证标准,通过系统的每个交易都被分类为有效或无效,这一步发生在最终提交之前。这种延迟中止(late abort)形式的一个严重缺点是,在早期阶段已经违反验证标准的交易仍在处理并传递给所有节点。这不仅让整个系统做了许多无用功,还会延迟向客户端发出交易无效通知的时间。
4.2.1 Violation in the simulation phase (cross-block conflicts)
来看看 Fabric 是如何处理模拟执行阶段发生的冲突交易的:假设有四个交易 T1、T2、T3 和 T4,它们当前处于排序阶段并最终形成大小为 4 的块发给所有节点验证。在节点 P 内开始该块的验证之前,交易提议 T5 的智能合约在 P 中开始模拟。为此,它获取整个当前状态的 read lock。当 T5 模拟执行时,块必须等待验证,因为它必须获取当前状态的独占 write lock。
这种情况下的问题是:如果 T1、T2、T3 或 T4 将写入由 T5 读取的键值,那么 T5 对过时的数据进行模拟。因此在读取的那一刻,交易就已经变得无效。可是 Fabric 在 T5 的验证阶段之前没有检测到这种过时的读取。因此 T5 将继续其模拟并经历排序阶段,只是最终被无效。
4.2.2 Violation in the ordering phase (within-block conflicts)
冲突除了发生在不同区块,也有可能发生在同一个区块内部:如 4.1 节所示,这种情况出现在排序之后。尽管块内 3/4 的交易实际上是无效的,也将传递给网络的所有节点进行验证。
尽早“清理”流水线的概念在数据库中被称为 early abort,它减少了网络流量并节省了计算资源。
5 FABRIC++
5.1 Transaction Reordering
对一组交易 S 重新排序时遇到的挑战:首先我们需要确定 S 中的哪些交易是相互冲突的。由于 S 中的交易在完全隔离的环境下模拟执行,这些冲突仍有可能会发生。因为 S 的提交发生在之后的阶段,它们没有机会看到彼此潜在的冲突修改。
假设 Ti 写入由 Tj 读取的键值(记为 Ti ↛ Tj),那么 Ti 必须排在 Tj 之后(记为 Tj ⇒ Ti),否则 Tj 将无效。如果发生冲突循环,简单的重新排序无法解决问题。比如 Ti ↛ Tj ↛ Tk ↛ Ti,这种情况下只有先删除某笔交易来形成一个无环子集。
五个步骤:
- 建立 S 的所有交易的冲突图
- 识别冲突图中的所有环
- 识别每一笔交易出现在哪个环中
- 依次中止出现在最多环中的交易,直到解决所有的环
- 使用剩余的交易建立一个可串行化调度
1 | |
5.1.1 Example
假设有六个交易 T0 到 T5,一共访问了十个键值 K0 到 K9。
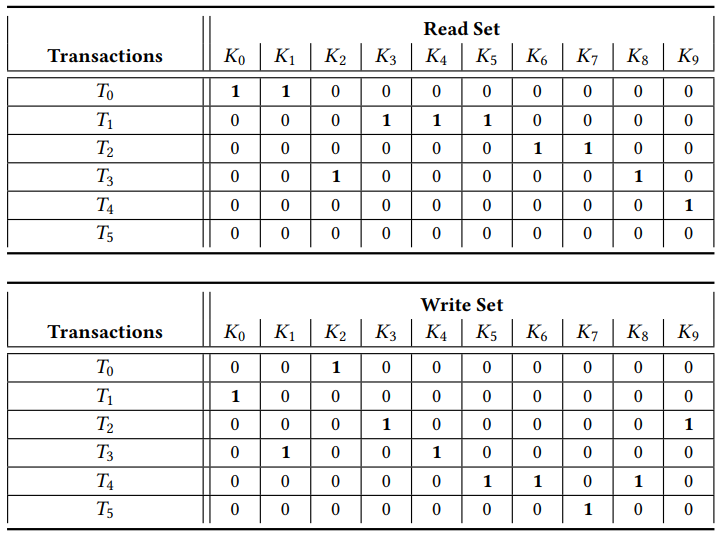
Step 1:建立交易冲突图。
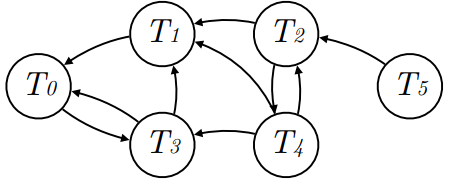
Step 2:我们应用 Tarjan 的算法来识别所有强连通子图,使用 Johnson 的算法识别强连通子图中的所有环。第一个子图有两个环,第二个子图有一个环,第三个子图无环。
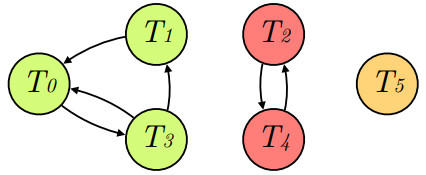
Step 3:标记每一笔交易所在的环。
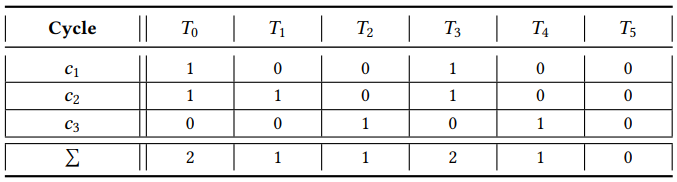
Step 4:首先处理所在环数最多的交易 T0 和 T3,移除下标较小的一个 T0 以保证算法的确定性,这步操作清除了 c1 和 c2 两个环。接着移除 T2 清除 c3,使图变为无环状态。我们可以从剩下的交易子集 S’ = {T1,T3,T4,T5} 建立无冲突调度序列。
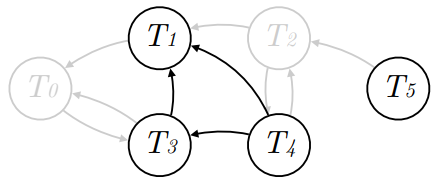
Step 5:重复执行以下两步,直到所有节点都被 scheduled:(a) 定位当前子图源节点;(b) 对该源节点可访问的所有节点 scheduling。
首先从 C(S’) 中下标最小的交易 T1 开始(即代码中的 startNode),我们必须找到 T1 的源节点,将它排在最后。T1 有两个父节点 T3 和 T4,T3 没有被访问过但是它有父节点 T4,T4 没有被访问过且是源节点,因此我们将 T4 放在 schedule 的最后一个位置。
图中 T4 能够到达的所有节点都要排在它前面,T4 有两个子节点 T1 和 T3,T1 没有被 scheduled,但是 T3 指向 T1,所以不能直接 schedule T1。我们访问 T3 并发现它有一个父节点 T4 是源节点,所以将 T3 排在 T4 之前,T1 排在 T3 之前。到此,源节点能够到达的节点都排完了,然后再对剩下的节点进行排序得到 T5 ⇒ T1 ⇒ T3 ⇒ T4。
请注意,我们的重新排序机制并不能保证中止最少数量的交易,因为这将是一个 NP 难题。然而它提供了一种非常轻量级的方法来生成一个可串行化的调度,只需要少量的中止。
5.1.2 Batch Cutting
上述讨论忽视了排序服务的出块操作,我们在 Fabric 原有出块条件的基础上加入了一个条件:批处理中交易访问的键值达到一定数量。这个条件确保了我们的重新排序机制的运行时间保持有界。
5.2 Early Transaction Abort using Advanced Concurrency Control
重排机制将交易中止时间从验证阶段提前到了排序阶段。
5.2.1 Early Abort in the Simulation Phase
为了在模拟阶段实现 early abort,必须通过更细粒度的并发控制机制来扩展 Fabric,该机制允许在 Peer 中并行执行模拟和验证。有了这样的机制,我们就有机会在模拟过程中识别过时的读取。
再来看看 4.2.1 的例子,在细粒度的并发控制机制下,当提案 T5 的智能合约正在模拟时,包含 T1、T2、T3 和 T4 的块将不必等待验证,这四个交易将以原子方式应用它们的更新。对于 T5 执行的每一次读取,我们都可以检查读取值是否仍然是最新的。一旦检测到过时的读取,就可以中止对 T5 的模拟并直接通知相应的客户,以便其重新提交提案。
如何实现:在现代数据库系统的背景下,高级并发控制机制已经建立起来。这种技术通常在记录级别甚至在单个单元/值级别执行细粒度锁定,而不是锁定整个存储。由于数据库系统的存储和 Fabric 中使用的存储在概念上没有区别,因此可以在这里应用类似的技术。
Fabric 用键值对存储其当前状态,该存储将每个单独的键映射到一对值和版本号。版本号实际上由执行更新的交易 ID 以及块 ID 组成,其唯一目的是识别过时的读取。我们在 Fabric++ 中删除读写锁,因为使用每个值维护的版本号足以确保与 Fabric 相同的交易隔离。为了确保并行运行的模拟阶段不会读到验证阶段执行的更新,我们在模拟过程中检查每个读取值的版本号,并测试它是否是最新的。

在模拟阶段开始时,首先识别账本的最后一个区块 ID,在此记为 last-block-ID。如图 last-block-ID = 4。在模拟执行期间,任何读取的版本号所包含的 block-ID 都不应该高于 last-block-ID,否则该值在交易模拟阶段已经被更改而过期。模拟阶段中的 balA=70 的读取发生在验证阶段将 balA 更新为 50 之前。因此读数是最新的,模拟仍在继续。balB 的读取发生在验证阶段将 balB 更新为 100 之后。由于 5 高于 last-block-ID = 4,我们可以直接将该交易标记为无效,因为交易将没有机会通过验证阶段。
5.2.2 Early Abort in the Ordering Phase
由于 Fabric 以整个块的粒度执行提交,因此同一块中读取相同键的两个交易必须读取相同版本。因此一旦检测到同一块内的交易之间的版本不匹配,就可以提前中止后一个交易。这种策略确保只有那些有提交机会的交易最终会进入块中。
6 EXPERIMENTAL EVALUATION
6.1 Setup
略
6.2 Benchmark Framework and Workload
6.2.1 Framework
主要使用自己搭建的测试工具,也使用了 Caliper。
6.2.2 Workload
两种不同的工作负载:
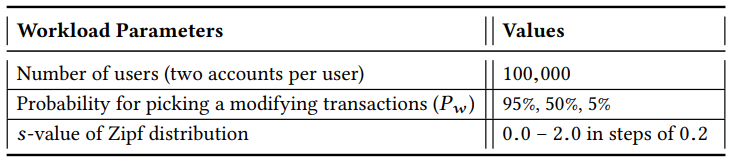
第一种是 Smallbank,它模拟了一个典型的资产转移场景。最初,它为一定数量的用户分别创建一个支票账户和一个储蓄账户,并用随机余额初始化它们。工作负载由六笔交易组成,其中五笔交易以某些方式更新账户余额:TransactSavings 和 DepositChecking 将储蓄账户和支票账户分别增加一定数额。SendPayment 在两个支票账户之间转账。WriteCheck 减少支票账户,而 Amalgamate 将所有资金从储蓄账户转移到支票账户。还有一个只读交易 Query 读取用户的支票以及储蓄账户。在一次运行过程中,我们以随机的方式重复发送这六个交易,其中我们以一定的概率 Pw 从五个修改交易中统一选择一个,以概率 1−Pw 读取交易。对于每个选择的交易,通过遵循 Zipfian 分布来确定要访问的帐户,可以通过设置 s 值来进行配置。
第二种工作负载仅由一个高度可配置的交易组成,对一组帐户余额执行一定数量的读写访问。最初,我们创建一定数量的帐户(N),每个帐户都用一个随机整数初始化。交易对这些帐户的一个子集执行一定数量的读写(RW)。在这些帐户中,存在一定数量的热帐户(HSS),它们具有更高概率的读写访问。可以分别配置用于读取(HR)和用于写入(HW)的热帐户的概率。在一次运行中,我们以一定的概率在一定的时间内发送固定的交易流。
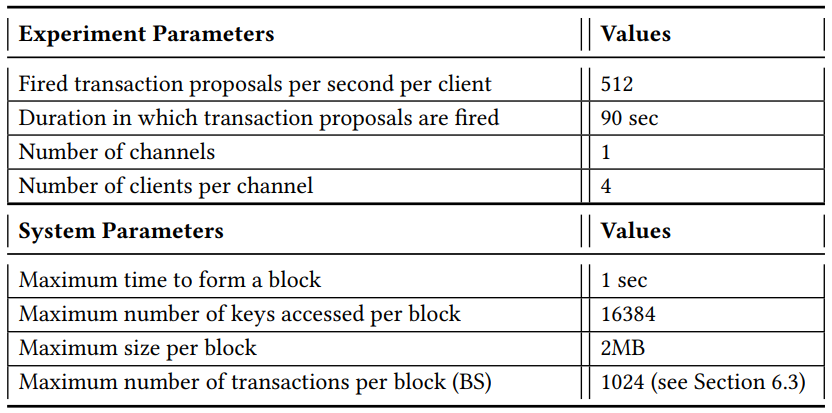
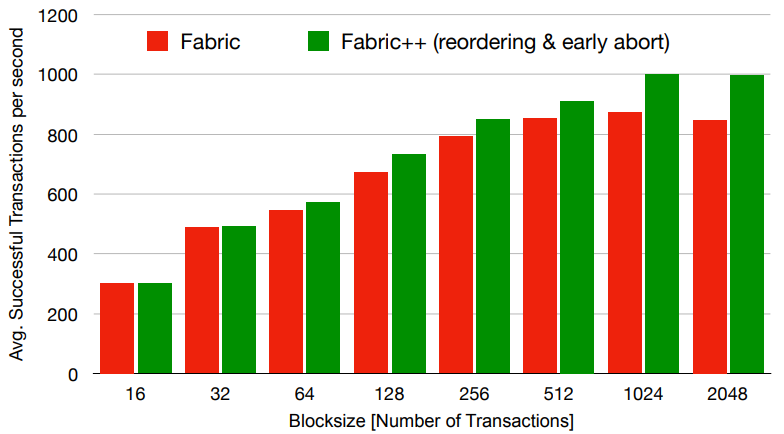
6.3 The Impact of the Blocksize
我们通过调查块大小对 Fabric 和 Fabric++ 的影响来开始测试。默认情况下,Fabric 的 sample network 将块大小限制为最多 10 个交易。在下面的实验中,我们以对数递增将块大小从 16 增加到 2048,并观察成功交易数量。Smallbank 作为工作负载,有 100000 名用户 Pw = 95% 的高写工作负载和 s = 0 的均匀分布。下图展示了总共 90 秒运行时间里每秒的平均成功交易数。
6.4 Transactional Throughput
6.4.1 Throughput under Smallbank
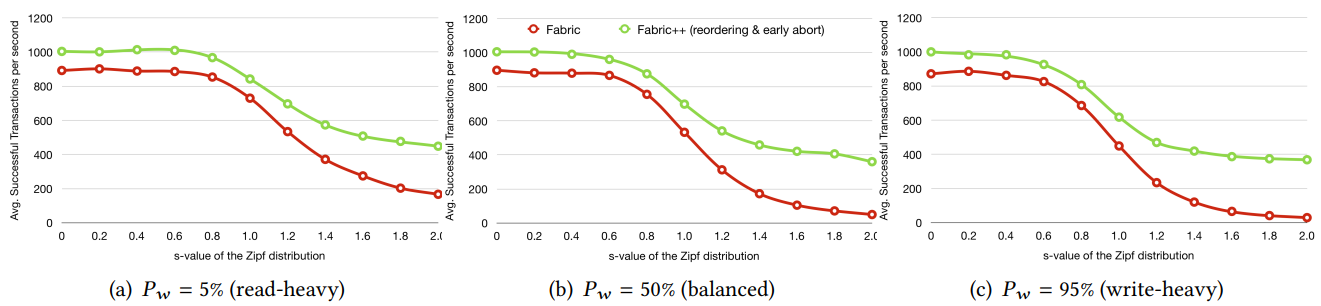
6.4.2 Throughput under custom workload
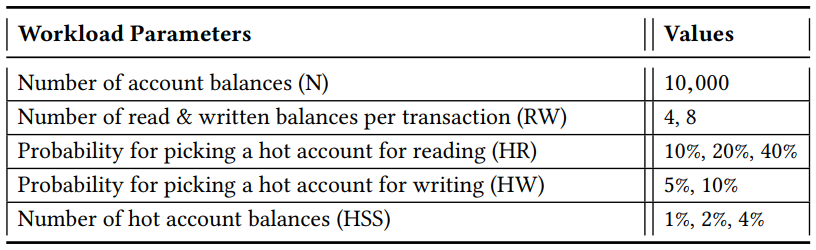
6.4.3 Observations
Fabric++ 倾向于选择更多访问较少键值的交易,而不是选择少数访问次数较多的交易,以提高成功交易的端到端吞吐量。对于可能具有非冲突读写集的工作负载,Fabric++ 能够重新组织交易块,以最大限度地减少不必要的中止次数。
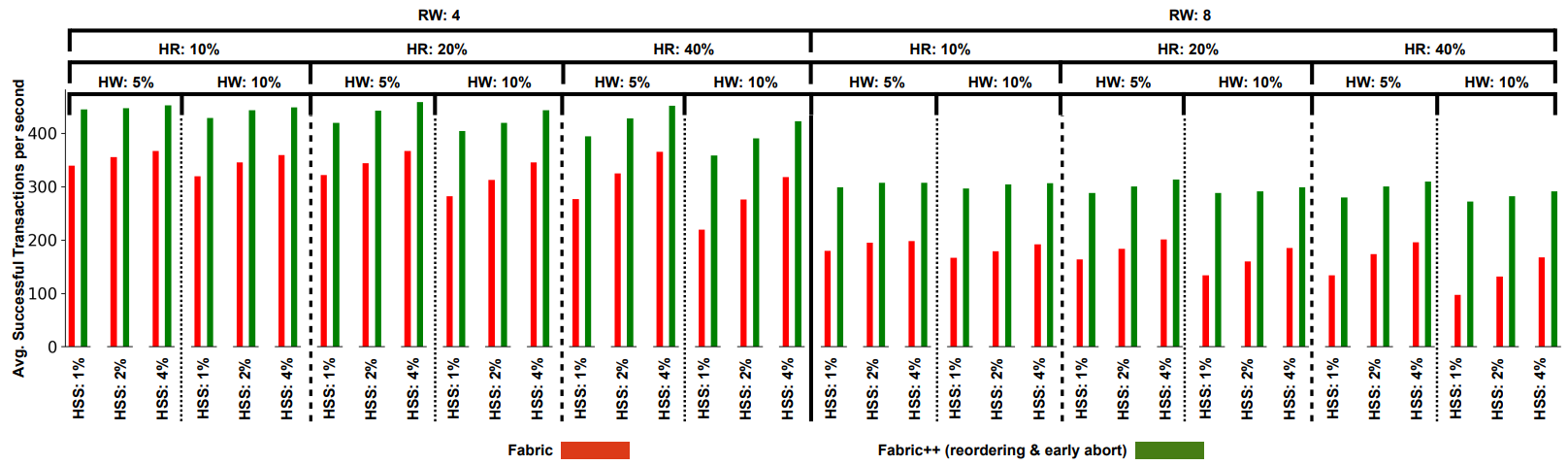
6.5 Optimization Breakdown
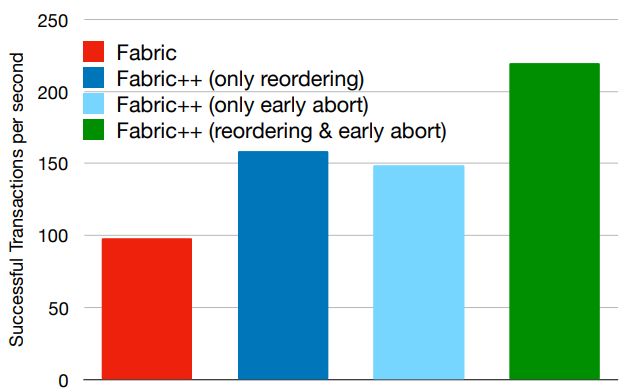
6.6 Scaling Channels and Clients
之前的实验是在单通道四客户端进行的,接下来改变这两个配置。
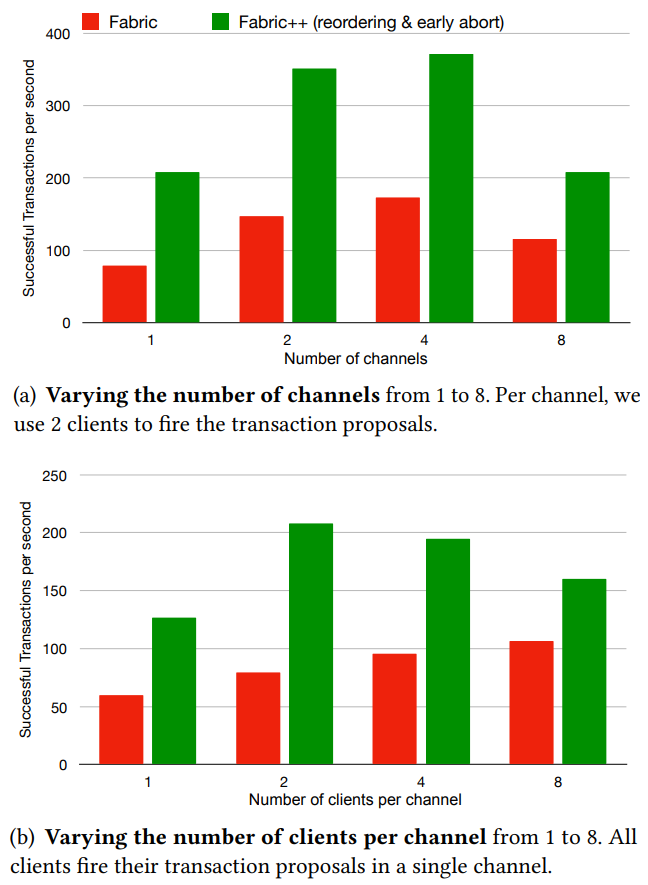
6.7 Hyperledger Caliper
Caliper 在高交易触发率下受影响严重,所以我们用四个客户端分别以 150 交易每秒发送交易,总共 600 交易每秒。

7 CONCLUSION
略
8 ACKNOWLEDGEMENT
略