「论」 A Transactional Perspective on Execute-order-validate Blockchains
本文最后更新于:1 年前
Hyperledger Fabric 支持交易并行化执行,但却在序列化时可能会呈现许多无效交易。受到现代数据库乐观并行控制技术启发,我们提出了一种通过对交易重新排序来减少中止率的方法改进 execute-order-validate 架构。
1 INTRODUCTION
新的 EOV 结构将交易的执行细节限制在背书节点,从而增强了机密性并使用了并发性。但这样的并发性是以中止不符合序列化的交易为代价的。
解决这个问题有两个方向:一是改进 Fabric 的体系结构,以提高其可达到的吞吐量,例如 FastFabric;二是是抽象出交易生命周期,以降低中止率,例如 Fabric++。本文工作选取第二个方向,作为区块链“数据库化”的主要尝试。
我们分析了当前 Fabric 和 Fabric++ 的实现,发现两者都有强可串行性(Strong Serializability)。这种实现比原始 Fabric 协议规定的单拷贝可串行性(One-Copy Serializability 或 simply Serializability)更严格。这两个系统都采用了一种预防性方法,这种方法可能会过度中止仍然可以序列化的交易。我们的提案包括一种新的重新排序技术,该技术消除了由于分类账内冲突而导致的不必要的中止,并建立可序列化性保证。贡献如下:
从理论上分析了具有 EOV 架构的区块链和具有乐观并发控制的数据库中事务处理的相似性。基于这种相似性分析了最先进的 EOV 区块链的交易行为,如 Fabric 和 Fabric++。
提出了一个新的定理来识别那些永远无法重新排序以实现序列化的交易。基于这一定理提出了有效的算法来早期过滤掉此类交易,并为重新排序后的剩余交易提供可序列化性保证。还讨论了对安全的影响。
在两个现有的区块链之上实现了我们提出的算法。首先使用 Hyperledger Fabric v1.3 作为基础,并将实现命名为 FabricSharp(简称 Fabric#)。其次使用 FastFabric,它在 Fabric 的所有优化中获得了最高的吞吐量,并将实现命名为 FastFabricSharp(简称 FastFabric#)。
通过将 FabricSharp 与 Fabric、Fabric++ 和其他两个数据库并发技术进行比较。实验结果表明,与其他系统相比,FabricSharp 的吞吐量高出 25% 以上;FastFabricSharp 相对于 FastFabric 的提升高达 66%。
2 BACKGROUND
2.1 EOV architecture in Fabric and Fabric++
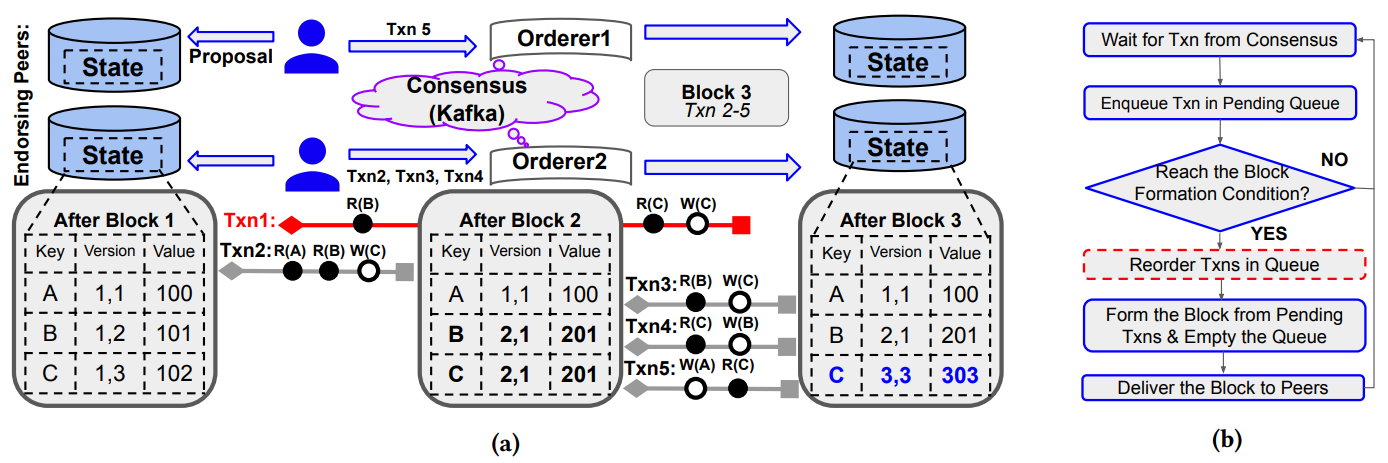
Fabric++ 在共识之后出块之前加入了对交易重新排序的步骤
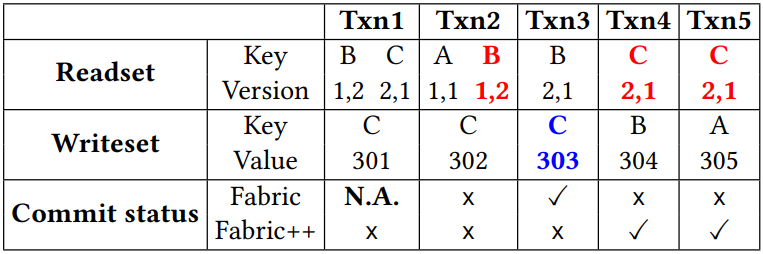
红色代表 staled reads,蓝色代表 installed writes,N.A. 代表 not-allowed transactions。
2.2 Optimistic Concurrency Control in Databases
考虑到快照隔离会出现异常(如丢失更新和写入偏移),已多次尝试将快照隔离转换为可串行化级别。
3 THEORETICAL ANALYSIS
3.1 Resemblance in Transaction Processing
Definition 3.1 (Blockchain snapshot). 区块链快照是提交区块后区块链的状态。设 M 为提交块的序列号,则对应的快照表示为 M,并称其具有序列号(M+1, 0)。
Definition 3.2 (Snapshot consistency). 如果存在可以读取交易的所有记录的区块链快照 M,则交易是快照一致的。
Fabric 中的交易满足快照一致性,因为 Fabric 使用锁来确保模拟是从最新状态开始进行的。Fabric++ 删除了锁,但提前中止了跨块读取的交易,所以也满足快照一致性。但是有些交易被过度中止了。
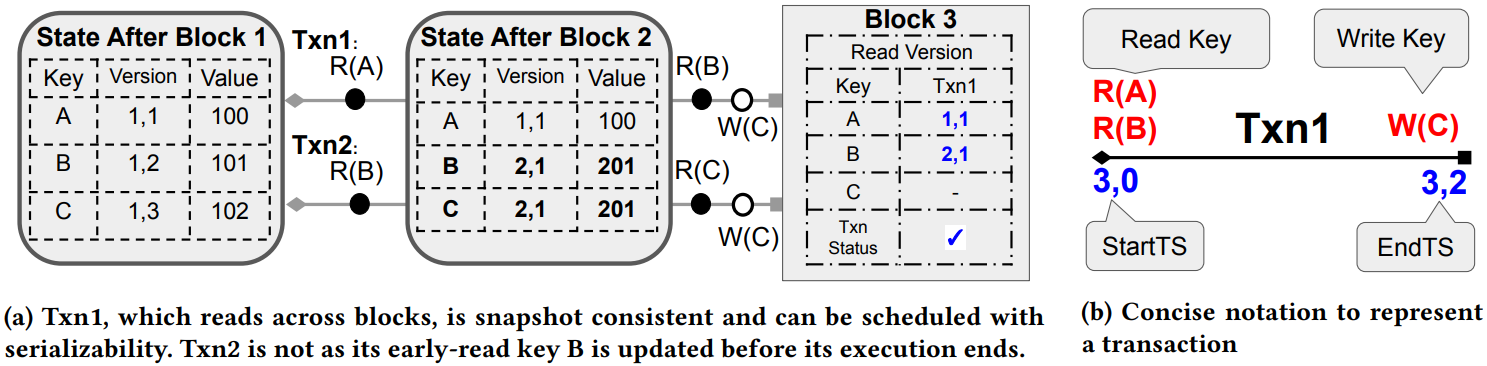
Example 3.3. 图 a 中,Txn1 读取快照 1 中的版本(1,1)的 A 和快照 2 中的版本(2,1)中的 B。这些版本与快照 2 中 A 和 B 的版本相同。因此,Txn1 是与块快照 2 一致的快照。相反,同样跨块读取的事务 Txn2 没有实现快照一致性,因为先前读取的 B 的值在块 2 中改变。
Proposition 3.4. 存在跨块读取的快照一致性交易,其块快照由其最后一次读取操作决定。
Proof. 图 a 中的 Txn1 是一个示例。我们在 Example 3.3 中描述了 Txn1 在块 1 和 2 之间读取,并且它仍然与块快照 2 一致。
Definition 3.5 (Start timestamp). 交易 Txn 的开始时间戳,由 StartTs(Txn) 表示,是其读取快照的序列号。
Definition 3.6 (End timestamp). 交易 Txn 的结束时间戳,由 EndTs(Txn) 表示,是其在块中的序列号,由共识确定。
如 a 中交易 Txn1 具有 StartTs(Txn1) = (3,0) 和 EndTs(Txn1) = (3,1),因为它最后从块 2 读取并占据块 3 中的第一个位置。为了简洁起见,我们在之后的叙述中简化为图 b 的样式。交易的开始或结束时间戳的序列号是按字典顺序排列的,例如 (2,1) < (2,2) = (2,2) < (3,0)。
Definition 3.7 (Concurrent transactions). 如果 Txn1 和 Txn2 的执行重叠,则称它们是并发的。
Proposition 3.8. 同一区块中的每对交易都是并发的。
Proof. 假设两个交易 Txn1 和 Txn2 分别在位置 p 和 q 处提交到同一块 M 中,其中 p < q。由于 Txn2 可以从中读取的最新块是 M−1,因此我们得出:StartTs(Txn2) ≤ (M,0) < EndTs(Txn1) = (M,p) < EndTs(Txn2) = (M,q)。因此,Txn1 和 Txn2 是并发的。
Proposition 3.9. 存在不属于同一区块的并发交易。
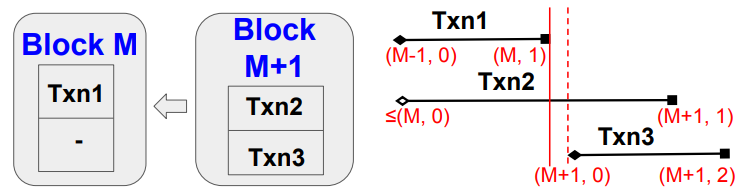
- Proof. 如图,其中 Txn1 和 Txn2 分别属于块 M 和 M+1,Txn2 从早于 M 的块中读取, StartTs(Txn2) ≤ (M,0) < EndTs(Txn1) = (M,1) < EndTs(Txn2) = (M+1,1)。因此 Txn1 和 Txn2 是并发的。
由上可见,并发不仅发生在同一块内的交易之间。Fabric++ 没有考虑跨块交易之间的依赖关系。因此,它的重新排序效果是有限的。
3.2 Serializability Analysis
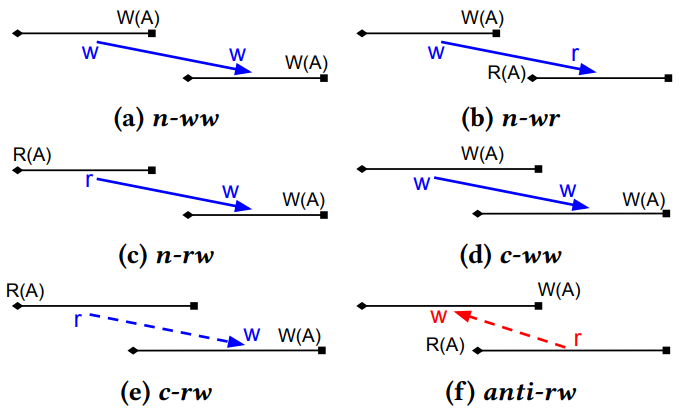
如图是快照交易依赖(或冲突)的六种场景。根据冲突可串行化定理,可串行化事务调度的效果等效于任何按照依赖顺序的串行化执行历史。请注意,可序列化事务调度的依赖关系图必须是无环的。
Definition 3.10 (Strong Serializability). 如果交易 schedule 的效果等效于序列化的历史记录,则交易 schedule 是强可序列化的。该历史记录符合交易的提交顺序,该顺序由交易的结束时间戳确定。
Theorem 3.11. 没有 anti-rw 交易的 schedule 实现了强可序列化。
Proof. 首先证明任何没有 anti-rw 交易的 schedule 实现了可序列化:通过反证法,假设一个 schedule 不能实现可序列化,那么其中必然有一个交易子集具有环形依赖,环里最后提交的交易由 Txn 表示。那么 Txn 必须具有 anti-rw 依赖关系,因为 anti-rw 是唯一从后面的交易指向前面的依赖关系,这与假设不符。因此 schedule 实现了可序列化。下一步证明实现了强可序列化:由于其余五个依赖的顺序与其提交顺序一致,因此遵循提交顺序的序列化历史也遵循依赖顺序。根据冲突可串行化定理,这种序列化的交易历史具有可序列化 schedule 的等效效果。因此,schedule 是强序列化的。
我们注意到 Fabric/Fabric++ 不允许在两个交易之间的 anti-rw,因为后一个交易将读取前一个更新的旧版本,因此必须中止。可见 Fabric/Fabric++ 满足强可序列化。
3.3 Reorderability Analysis
在可序列化而非强可序列化下,我们分析了 EOV 区块链中交易的可重新排序性。我们通过改变待定交易的提交顺序来确定可序列化的 schedule。
Lemma 3.12. 在区块链中,重新排序只能发生在并发交易之间。
Proof. 假设交易重新排序发生在两个非并发交易之间。由于 Proposition 3.8,这些交易在不同的区块中进行。改变它们的顺序意味着更改先前提交的块,这在区块链中是不可能的。
Lemma 3.13. 交易在重新排序后不会改变其相对于其他交易的并发关系。
Proof. 易证。
上面的 Lemma 3.12 确保了重新排序不会影响非并发交易及其依赖关系。Lemma 3.13 确保非并发交易不会被重新排序引入。因此,我们将分析限制在并发依赖关系上。我们使用下面的两个引理来描述并发交易的依赖顺序。
- Lemma 3.14. 如果两个交易 Txn1 和 Txn2 表现出 c-rw 或 anti-rw 依赖性,则改变提交顺序不会影响它们的依赖顺序。
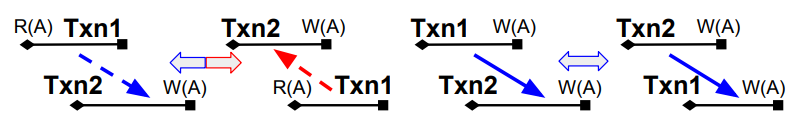
Proof. 当 Txn1 和 Txn2 表现出 c-rw(或 anti-rw)依赖性时,如果我们切换它们的提交顺序,它们将表现出 anti-rw(或 c-rw)依赖性。因此,在这两种情况下,它们的依赖顺序保持相同,即 Txn1 读取一个键值,该键值稍后将由 Txn2 写入。
Lemma 3.15. 如果两个交易 Txn1 和 Txn2 表现出 c-ww 依赖性,切换它们的提交顺序将翻转它们的依赖顺序。
Proof. 当 Txn1 和 Txn2 表现出 c-ww 依赖性时,Txn1 的写入将被 Txn2 覆盖。如果它们的提交顺序被切换,Txn2 的写入将被 Txn1 覆盖。因此,Txn1 和 Txn2 的依赖顺序被翻转。
Theorem 3.16. 如果存在一个没有 c-ww 依赖关系的环,则 schedule 无法重新排序为可序列化。
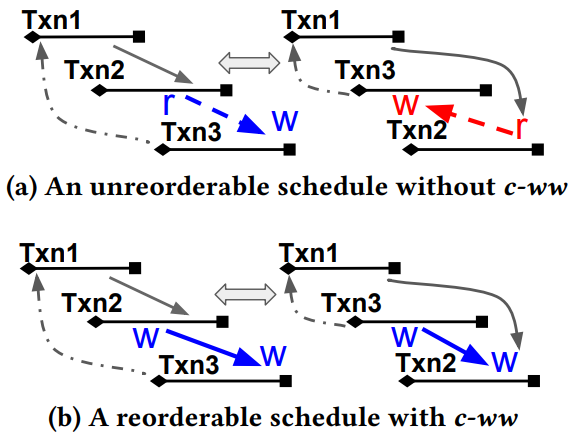
- Proof. 我们将循环中的依赖分为两类。第一类是在依赖中至少有一个已提交的交易。由于区块链的不变性,重新排序不会影响这些依赖关系,因为两个交易的相对提交顺序是固定的。第二类包括一对待定交易之间的所有依赖关系。对于每个依赖项,其对应的交易必须是并发的,否则前一个交易已经被提交。由于交易是并发的,且没有 c-ww,因此顺序只能在具有 c-rw 或 anti-rw 的冲突交易之间改变。尽管被重新排序,它们的依赖顺序仍然不变(Lemma 3.14)。如图 a,循环 schedule 仍然是不可序列化的。
然而,如果在待定的交易之间存在一个具有 c-ww 依赖的环,则 schedule 可以被重新排序为可序列化。Lemma 3.15 说明了它们的依赖顺序可以翻转。图 b 中由 Txn1、Txn2 和 Txn3 形成的循环调度通过交换 Txn2 和 Txn3 的提交顺序而变得可串行化。
3.4 Fine-grained Concurrency Control
Theorem 3.16 指出,在待定的交易中没有 c-ww 的循环 schedule,即使重新排序也无法序列化。基于此,我们为 EOV 区块链中的细粒度并发控制制定了以下三个步骤:
- 对于一个新交易,首先考虑所有待定交易(包括新交易)中除了 c-ww 的所有依赖项,如果存在依赖循环,将直接丢弃新交易。
- 在出块时,我们按照计算的依赖关系检索交易顺序。
- 根据检索 schedule 恢复对交易的 c-ww 依赖关系。
c-ww 依赖关系恢复仍然是必要的,因为未来不可序列化的交易可能会遇到一个包含已提交交易的 c-ww 依赖关系的循环。但它们的提交顺序和依赖顺序都已经固定。因此,依赖关系图在恢复之后仍然是非循环的。



其中算法 3 中的拓扑排序(topological sort)始终有解,因为 G 由算法 2 保证无环。
与 Fabric++ 中的重新排序算法相比,我们的算法更细粒度,因为不可序列化的交易在排序前被中止,并且剩余的交易保证是可序列化的而不会被中止。我们的重新排序不再局限于一个块的范围。另一个显著的区别是,在模拟开始时确定块快照,而 Fabric 和 Fabric++ 则根据上次读取操作来确定。为了获得更多的并行性,我们允许在模拟执行过程中进行块提交,但当模拟过程中提交的交易更新了以前读取的记录时,这可能会引入过时的快照。
3.5 Security Analysis
我们的重排算法是排序过程的一部分,需要在每个诚实的排序节点复制,以在共识建立交易顺序后形成账本。假设原始共识在其安全模型下实现了安全性和有效性,现在讨论在重新排序后这两个性质是否保持不变。
Safety. 在最初的 Fabric 设计中,有四个安全属性:agreement,hash chain integrity,no skipping 和 no creation。这要求诚实的排序节点在账本中连续交付一致的数据块,我们的方法保留了哈希链的完整性,并且没有跳过,因为不改变块形成过程。不引入新的交易,所以也没有创建。达成了一致,因为在每个排序节点上完全复制了重新排序,只要诚实的排序节点从一致的交易流中单独执行重新排序,就可以产生相同的账本。
Liveness. Fabric 根据 validity 属性定义了活性,该属性要求所有广播的交易都包含在账本中。由于我们的算法中止的交易被排除在账本之外,可能会破坏这种活性。然而,我们建议采取以下方法来防止滥用。在共识协议中,交易顺序是由领导者节点临时提出的。当这个顺序被其他节点接受时,它就成为了我们重新排序方法的输入。顺序由领导者控制,他可能利用公开的重新排序算法以恶意推迟某些交易。我们可以隐藏交易细节(如访问记录)来解决这个问题,比如客户端只给排序者发送交易哈希。在交易哈希的顺序确定后,再把交易细节公开给排序者来重新排序。
4 IMPLEMENTATION
4.1 Overview
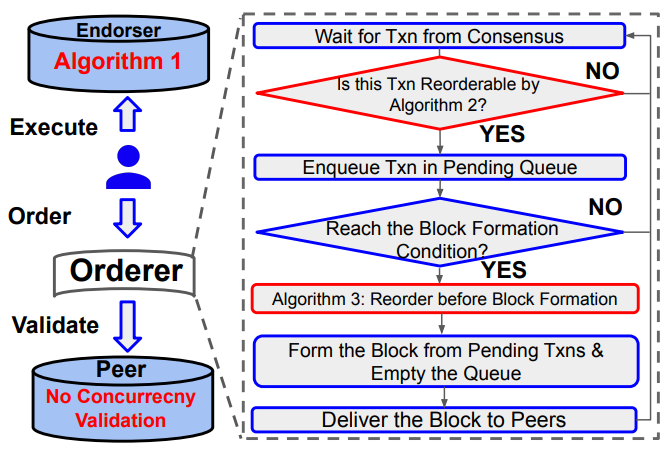
4.2 Snapshot Read
算法 1 中我们依靠存储快照(storage snapshot)机制来确保每个合约调用都是在一致的状态下进行模拟的。在每一个区块被提交的时候,我们都会创建一个存储快照并将其关联到区块号。每一笔交易在模拟执行之前都要获取最新的区块号,没有任何模拟的陈旧快照会被定期清理。这种设计允许在执行阶段的合约模拟和验证阶段的块提交之间有更多的并行性。原生 Fabric 使用读写锁来协调这两个阶段。
4.3 Dependency Resolution
为了计算算法 2 中的依赖图,我们在排序节点中引入了两个多版本存储,以识别已提交的交易。这些存储器在 LevelDB 中实现,分别表示为 CommittedWriteTxns(CW)和 CommittedReadTxns(CR)。CW 中的键由记录键和更新值的交易的提交序列组成:例如 Txn1 的提交序号是 (3,2) 写入 A 的值,CW 会记录 {A_3_2:Txn1}。CR 中的键由记录键和读取最新值的交易的提交序列组成:例如 {A_4_1:Txn7} 表示 Txn7(4,1) 读取键 A 的最新值。
CW.Before(key,seq) 返回序列号小于 seq 且更新 key 的最后一笔已提交交易。
CW.Last(key) 返回最后一个更新 key 的已提交交易。
CW[key][seq:] 返回所有在 seq 之后更新 key 的已提交交易。
我们在内存中维护两个索引,PendingWriteTxns(PW)和 PendingReadTxns(PR),分别存储待定交易的写入和读取集。如果一个新交易 txn 开始于 startTS,读取的键为 R,写入的键为 W,那么 txn 的所有依赖计算如下:
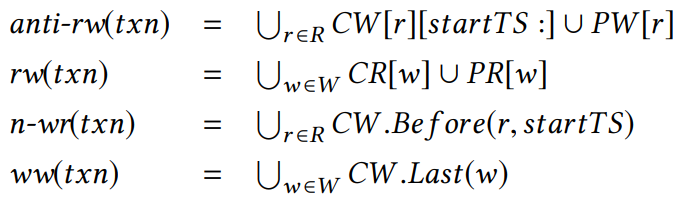
请注意,我们忽略待定交易之间的 ww 依赖关系,并且不区分 ww 和 rw 是否并发。这是因为非并发交易可能是一个环的一部分。然后将 txn 的 predecessor 计算为 ww(txn) ∪ n-wr(txn) ∪ rw(txn),将 successor 计算为 anti-rw(txn)。
4.4 Cycle Detection
本节讨论如何使用依赖图 G 来检测环并实现可序列化。有两个设计选择:一方面我们可以只维护每个交易的当前链接信息,然后遍历图来检测环;另一方面可以维护每对交易之间的所有可达性信息。后者将开销从计算时间转移到空间消耗。我们通过维护交易的直接 successors (txn.succ) ,并用布隆过滤器表示所有可以到达 txn 的交易(txn.anti_reachable),来实现最佳设计。环检测可以直接通过对由 txn 的 predecessor 和 successor 组成的每对 (p,s) 测试 p.anti_reachable(s)。

我们使用布隆过滤器是因为它们具有内存效率,并且可以执行快速并集。然而,已知布隆过滤器会报告 false positives。如果过滤器向 txn 报告了一对相邻交易的 false positives,我们会预防性地中止 txn。如果报告所有交易对都是 negative,那么 txn 不属于 G 中的任何环。
算法 4 的一个问题是不断增长的 anti_reachable filter,这会导致单个布隆过滤器的 false positive rate 不断增长。我们使用两个布隆滤波器。一个布隆过滤器捕获在块 M 之后提交的交易,另一布隆过滤器捕捉在块 N 之后的交易。假设 C 是包含 G 中已提交交易最早的区块,我们保持 M < C < N,并使用第一个布隆过滤器检测可达性。一旦 C 变为 M < N < C,第一个布隆过滤器被清空,并开始收集当前区块的交易。我们使用第二个布隆过滤器检测可达性。这样限制了每个过滤器中只包含一定范围区块里的交易,使得 false positive rate 可以接受。为了安全起见,诚实的排序者必须使用相同的 M 和 N。
4.5 Dependency Restoration
本节展示将 ww 依赖按照提交顺序(待定交易 P 根据 G 的可达性的拓扑排序)加入依赖图 G。

算法 5 概述了恢复 ww 依赖关系的主要步骤。下图中的示例进一步解释了该算法。待定交易(用蓝色虚线边框标记)、提交序列、新的 ww 依赖关系(用蓝色实线标记)和拓扑排序的迭代顺序的依赖关系图的示例。不考虑 Txn0 和 Txn3 之间的 ww 依赖性(用蓝色虚线标记),因为它是隐式的。红色的 Txn1 由于过时而需要修剪。交易年龄以斜体表示。
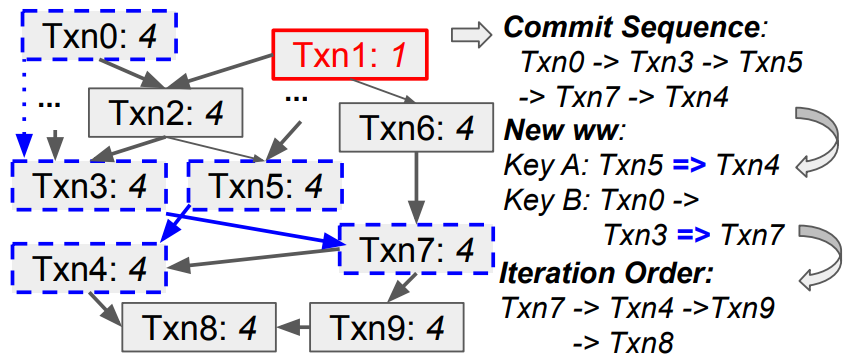
对于待定交易(PW)将要更新的每个 key,对其相关交易进行拓扑排序,并在可达性过滤器中选择尚未连接的第一对。在这样的对中,可以从第一个交易的所有 predecessors 到达第二个交易。如果一对中的交易已经在可达性过滤器中连接,这使得恢复是多余的:如图中 Txn0 和 Txn3。对于尚未连接的交易,需要更新它们的 successors。我们将交易放入 (head_txns) 集合中并根据拓扑排序更新 successors。这样可以在迭代中避免重复更新:例如 Txn8 在更新 A 和 B 时都可达,但使用这个算法可达性信息只会更新一次。
4.6 Dependency Graph Pruning
由于图 G 增长速度会很快,我们根据以下原则剪枝:(i) 根据非常旧的快照进行模拟;(ii) 无法影响待定交易。
对于第一种情况,我们引入一个参数 max_span 来限制交易的区块跨度(如果对块 M 模拟并在块 M+1 中提交,则其块跨度为 1)。如果下一个区块号是 M,我们计算 snapshot threshold:H = M − max_span。任何按照 H 或更早区块模拟的交易将会被中止。对于第二种情况,我们将交易 txn 的年龄定义为在 G 中的 txn 可到达交易的最后提交块的序列号。当 snapshot threshold 大于 txn 的年龄时,未来的交易不能与任何可以达到 txn 的交易并发。这种情况下 anti-rw 依赖就不会产生,并且这排除了任何包含 txn 的不可序列化的调度。因此,txn 可以安全地从 G 中剪枝。我们通过将 G 中的所有交易安排到按年龄加权的优先级队列中来修剪。对于要在块 M 中提交的新交易,我们在算法 4(第 7 行)中的遍历过程中将其可到达的交易的年龄增加到 M。为了安全起见,所有排序节点必须使用相同的 max_span 值。
5 EXPERIMENTS
5.1 Systems and Setup
基于 Hyperledger Fabric 1.3 改进并命名为 FabricSharp。与原生 Fabric 和两个采用 OCC 技术的系统比较。基于 FastFabric 改进并命名为 FastFabricSharp。每组实验采用两个排序节点,三个 Kafka 节点和四个对等节点。
5.2 Workloads and Benchmark Driver
我们采用与 Fabric++ 同样的工作负载—— Smallbank benchmark。一笔交易分别读取和写入 1 万个账户中的 4 个银行账户。我们将其中 1% 设置为热门账户。每次读取都有一定的概率访问热门帐户,由 Read hot ratio 参数控制。类似地,对热门帐户的写入由 Write hot ratio 控制。我们引入了另外两个工作负载参数,即 Client Delay 和 Read Interval。前者控制客户端在从对等节点接收到执行结果后向排序节点广播的延迟,模拟客户端的网络传输延迟。后者通过控制连续读取之间的间隔来模拟计算量大的交易。
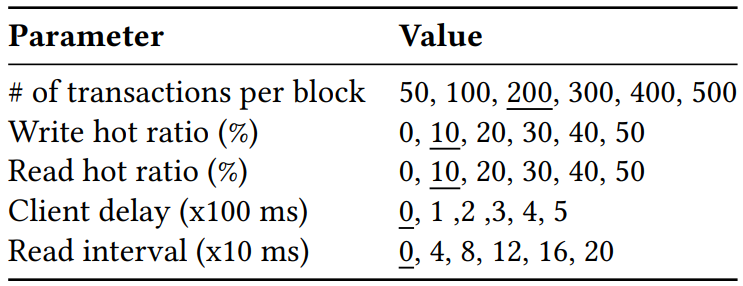
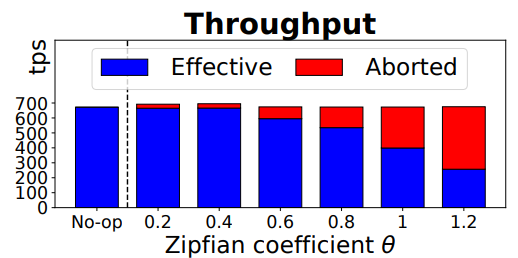
参数设置如图,画横线的是默认值。我们固定 max_span 为 10,请求速率 为 700 tps,这是因为 Fabric 在我们的设置中可以维持约 700 tps 的最大原始吞吐量。除非有特别说明,否则所有的吞吐量都指有效吞吐量,即通过序列化检验并持久化状态的交易。
5.3 The Performance of FabricSharp
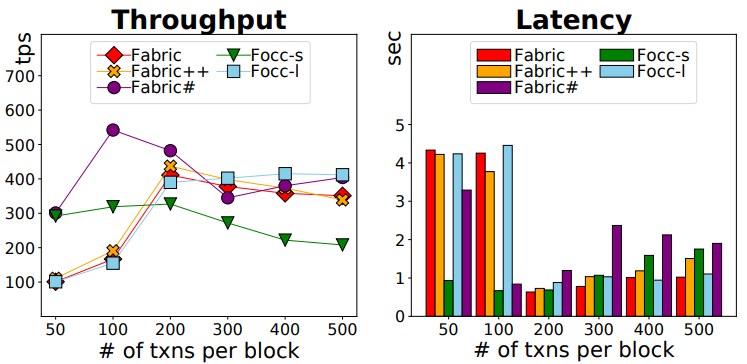
- Block Size.
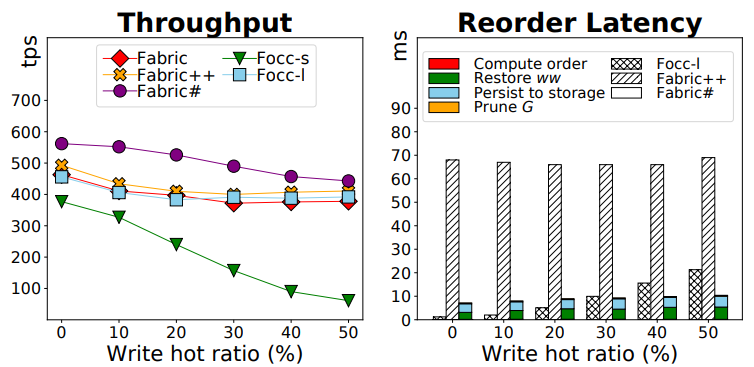
- Write Hot Ratio.
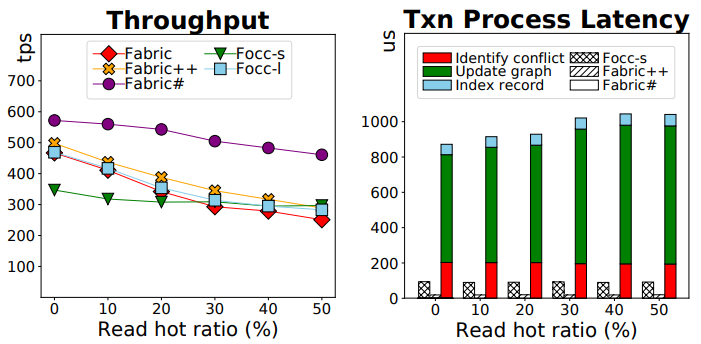
- Read Hot Ratio.
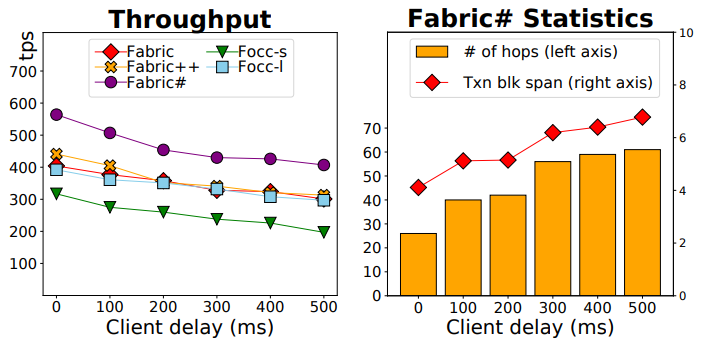
- Client Delay.
- Read Interval.
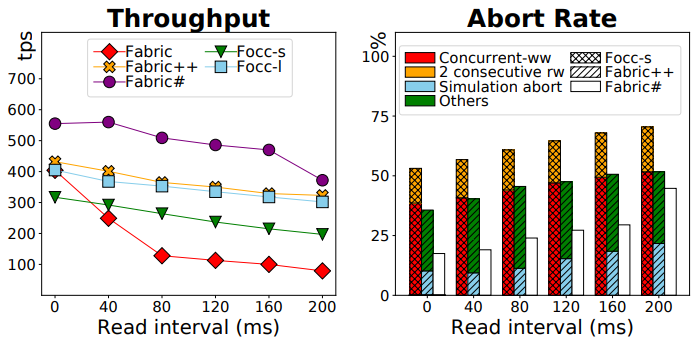
5.4 The Performance of FastFabricSharp
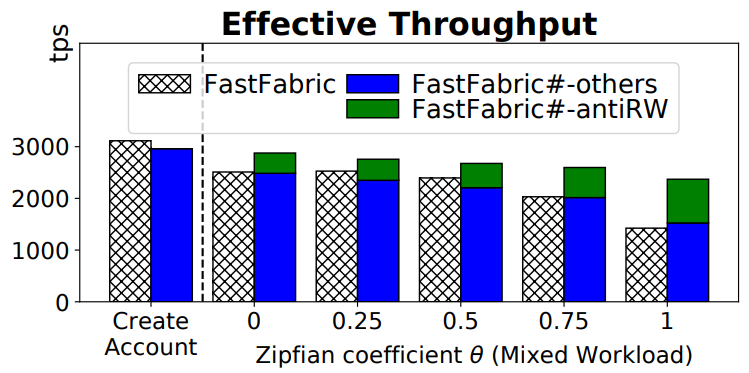
6 RELATED WORK
略
7 CONCLUSIONS
略