「论」 Utilizing Parallelism in Smart Contracts on Decentralized Blockchains by Taming Application-Inherent Conflicts
本文最后更新于:1 年前
区块链系统随着共识技术的发展,性能已经大大提高,交易执行成为一个新的性能瓶颈。我们观察到应用内在的冲突是限制并行执行的主要因素。本文提出使用分区计数器和特殊的可交换指令来打破应用程序冲突链,以最大化性能。我们还提出了 OCC-DA,一个具有确定性中止的乐观并发控制调度器,使得在公链中使用 OCC 调度成为可能。
1 INTRODUCTION
为了了解现有交易工作负载中可以利用的并行度,本文实证研究了一段历史以太坊交易。我们的发现:
- 与串行执行相比,并行可实现的总体加速限制约为 4 倍。虽然有许多块的执行速度随着线程数量的增加而增大,但很大一部分块的执行情况要差得多。
- 大多数块都被单个交易依赖链所阻塞,这些交易需要串行执行,因此影响了总体的执行时间。
- 对瓶颈交易的人工检查显示,它们中的大多数在单个计数器或数组上发生冲突。从应用程序的角度来看,大多数瓶颈交易可以分为三类:代币分发、收藏品和去中心化金融。
研究结果表明,我们工作的重点应该是消除智能合约中这些常见的争用源,而不是优化调度器的实现。本文提出了三种独立的技术来消除上述瓶颈:
最简单方法是使用多个发送方地址。手动将单个发送方的一组交易划分为多个不相交的交易集。
第二种方法是使用分区计数器(partitioned counters),类似于 Sloppy Counters。在这种方法中,我们维护几个子计数器,它们的总和构成原始计数器的值。写入基于某些属性(例如发送方地址)被路由到不同的子计数器并在其上操作。分区计数器可以减少任何两个写入交易冲突的概率。
第三种方法是消除由虚拟机级别的交换更新引起的可避免冲突。两个增加计数器但不使用其原始值的交易在语义上是可交换的。然而,在当前的以太坊虚拟机语义下,这些增量被转换为读取(SLOAD)和写入(SSTORE)指令,这将导致读写冲突。我们提出了一个名为 CADD(commutative add)的新指令。在给定状态条目上没有其他读写操作,而只有 CADD 操作的两个交易被视为不冲突。增量在交易提交期间逐个应用。
上述方案可以达到 18 倍以上的提速。此外,为了解决并行执行导致节点状态不一致问题,我们引入了一种具有确定性事务中止的乐观调度器。这种方法允许我们引入并行性的激励措施,以换取可接受的性能影响。
2 BACKGROUND AND MOTIVATION
为了解决 Bitcoin 和 Ethereum 的性能瓶颈,大家都做了很多努力。
在并行执行研究上,通过调查以太坊的历史工作负载,我们发现必须按顺序执行的一系列交易的许多关键路径都是由共享全局计数器的使用引起的。我们认为,进一步提高实际工作负载并行性的重要方法是引入更好的编程范式,使开发人员能够更容易地表达并行性,同时保持原始语义。并且需要对激励机制进行一些新的设计,以使该范式适用于现实世界的应用。
3 EMPIRICAL STUDY
3.1 Methodology
我们使用以太坊历史交易对现实世界数据集(2018 年 1 月 1 日到 2018 年 5 月 28 日共 8582236 个区块)中存在的并行性进行了实证研究。本实验的主题是智能合约存储冲突,即同一块内的两个交易访问状态树中的同一条目,并且这些访问中至少有一个是写入。
考虑到交易的执行时间是未知的,并且可能因节点而异,我们使用从交易收据中获得的 gas 成本作为近似值。
从交易的状态访问跟踪和 gas 成本导出的依赖性,我们为每个块构建了一个依赖图。然后,模拟在 2、4、8、16 和 32 个线程上的非抢占式执行,我们为每个块构建了一个最优调度。确保不需要中止任何交易的调度,同时最大限度地提高线程利用率。在这种执行模型下,该计划的总体执行成本为我们能够实现的潜在加速设定了上限。
3.2 Results and Findings
Execution Bottlenecks. 该实验揭示了我们在并行执行以太坊交易时可以实现的加速限制。我们发现,与串行执行相比,观察到的总体加速仅为 4 倍,考虑到我们有 8 个、16 个甚至更多的线程可用,这一结果并不令人满意。许多区块的加速效率很高,但也有相当一部分区块的性能很差。
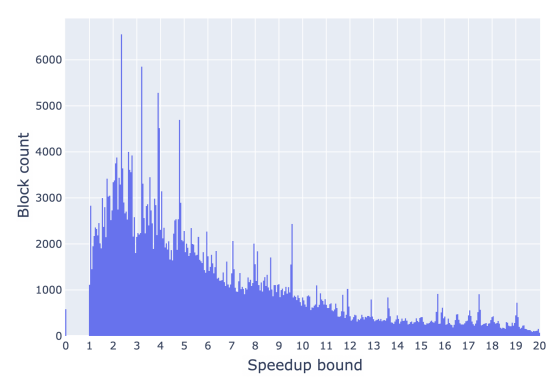
将一个块的执行成本与其依赖图中最重路径的执行成本进行比较时,我们发现这两者经常重合,这意味着性能瓶颈在最重路径的执行上。这往往是块中的某一笔交易,而我们想解决的是两笔或更多交易之间的瓶颈冲突链。所以我们又进行了一次实验,以 30 个块为一批并行执行。这相比串行执行速度提高了 9.46 倍,我们观察到:瓶颈通常在几十个或几百个依赖交易所组成的单个依赖链。
Classification of Smart Contract Conflicts. 我们确定了三大类:ERC20 代币(代币分发、空投)占样本瓶颈的 60%,去中心化金融(DeFi)应用程序占 29%,而游戏和收藏品(不可替代代币、NFT)占 10%。
Bottleneck Code Examples.
1 | |
当调用 transfer 时,发送者的余额被记 debited,而接收者的余额被记 credited。发送方的余额对应于状态树中的一个特定存储位置。借记操作将编译为加载(SLOAD)、添加(ADD)和存储(SSTORE)操作等。当两个交易同时从同一个发送方地址触发此函数时,将导致冲突。
1 | |
在以太坊流行的 CryptoKitties 游戏中,每个新的收藏品都存储在一个数组中。Solidity 数组上的 push 操作将修改两个存储条目:首先,它将把新项目存储在从数组长度导出的位置,其次,它将增加数组长度。两个并发交易都会修改数组长度,因此它们会发生冲突。
3.3 Generalizability of the Observations
我们相信所选择的时间段代表了当今以太坊的工作量,因此我们的发现是普遍的。
4 AVOIDING APPLICATION INHERENT CONFLICTS
由第三章可以看出,很大一部分存储冲突与计数器或数组的存储槽相关联。这里所说的计数器(counter)是指一个变量,无论其当前值如何,都可以通过递增或递减来跟踪一个量。Solidity 中的数组(Arrays)是一种简单的数据结构,用于存储元素序列和元素数量。
为了减轻交易瓶颈链的影响,我们需要通过消除所涉及的交易子集之间的依赖关系,将它们分解为多个较短的链:
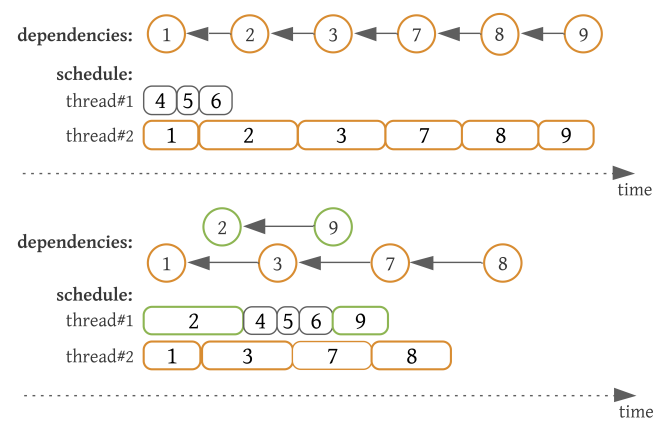
Technique 1: Conflict-Aware Token Distribution. 我们发现代币分发是迄今为止瓶颈冲突最常见的来源。在大多数情况下,冲突的来源是存储发送者帐户当前余额的条目。
最简单方法是使用多个发送者地址。通过将初始资金(在适用的情况下)分配给一组发送方账户,而不是单个账户,并对连续的交易使用不同的发送方地址,我们可以将瓶颈交易集划分为不相交的冲突交易集,每个交易集都不太可能形成瓶颈。
Technique 2: Partitioned Counters. 使用一种类似于 Linux 内核中 sloppy counters 的技术,我们提出了一种将同一计数器上的多个写入路由到多个不同存储条目的方法。由于对不同存储条目的写入不会发生冲突,因此可以大幅降低冲突率。
1
2
3
4
5
6
7
8
9
10
11
12contract PartitionedCounter { // LEN = 3
int256[LEN] public cnt;
function add(uint32 n) internal {
uint8 slot = uint8(tx.origin) % LEN
cnt[slot] += n;
}
function get() internal view returns (int256 sum) {
for (uint8 i = 0; i < LEN; ++i) {sum += cnt[i];}
}
}这里我们有一个单独的合约,它代表一个计数器实例。计数器的值实际上保存在 3 个称为子计数器的独立存储条目上。每次交易修改计数器的值时,我们都会根据发送方地址分配一个子计数器。由于地址是使用加密哈希导出的,因此可以将其视为伪随机子计数器分配。读取计数器的值时,将访问所有子计数器,并对其值进行求和。
给定交易的写入操作即使多次递增计数器也都将在单个存储条目上进行,因为在整个交易执行过程中,发送方地址不会更改。来自两个不同发送方地址的两个交易都增加了计数器,但在同一子计数器上操作的机会大大减少,因此通常可以避免冲突。也可以根据计数器使用频率分派不同的子计数器数量和路由规则(本例是根据发送方地址)。
此方案的缺点在于虽然我们只需要访问一个存储条目来写入计数器,但读取它将涉及到所有子计数器。因此,任何读取计数器的交易都将与所有写入交易发生冲突。因此,这种技术适用于 write-heavy 计数器。幸运的是,我们分析的许多计数器从来都不是通过交易读取的。其次,分区计数器可能比内置整数开销大得多,尤其是在读取计数器时。分区计数器提供的并行加速抵消了这一缺点。
Technique 3: Commutative EVM Instructions. 我们已经讨论了两种方法。一种是在应用程序级别,通过引入与应用程序交互的特定方式来解决冲突。另一种是在智能合约层面上,通过向合约开发人员提供工具来避免冲突。第三种方法是通过使用具有更好的冲突容忍度的新指令来扩展协议,从而在虚拟机级别上解决冲突。
当以太坊虚拟机(EVM)执行增量操作时,它首先将存储条目的当前值加载到内存中(SLOAD),然后修改该值(ADD),最后将最终结果存储回存储条目中(SSTORE)。两个交易递增同一计数器将同时读取和写入同一存储条目,因此它们将发生冲突。
对于计数器增量,当前值仅用于计算新值,所以与其他读写冲突不同,增量是可交换的(commutative),即递增同一计数器但不使用其值的两个交易可以按任何顺序执行。然而,在 EVM 的当前语义下,这样的交易将发生冲突。
我们引入了特殊的语义,用于以不会导致冲突的方式执行增量。将增量编译成一条代表交换加法的 CADD 指令,而不是编译成 SSLOAD 和 SSTORE 指令。此指令以一个存储位置和一个值作为其参数。当虚拟机遇到 CADD 指令时,它不会立即执行加法,而是将此操作记录在内存临时存储器中。如果虚拟机遇到 SSTORE 操作,则会移除同一存储位置上挂起的 CADD 指令,因为它们已经被覆盖。如果虚拟机遇到 SLOAD 操作,它将首先在同一存储位置上执行所有挂起的 CADD 操作,然后将结果用于此 SLOAD。
在交易被执行之后,调度程序继续检查冲突。对同一存储位置的并发读取和写入构成冲突,但是如果两个交易在一个存储位置上只有 CADD 操作,而没有其他读取操作,则不认为它们有冲突。在这种情况下,这些 CADD 操作是在提交阶段是串行执行的。引入 CADD 指令以向 VM 发送交换操作的信号,使我们能够避免源自单个计数器上的主要交易冲突。
5 OCC WITH DETERMINISTIC ABORTS
5.1 Incentives in Parallel Scheduling
并行调度器的效率取决于各种因素,其中一些因素在用户的控制之下。因此,并行执行必须有一套激励措施,以最大限度地提高其有效性。这种激励制度的详细设计超出了本文的范围。
基于 OCC 的并行执行不可避免地会导致一些事务中止和重新执行。如果允许用户在没有任何惩罚的情况下故意触发中止,就会导致调度器的 DoS 漏洞。因此,我们的目标是定义一个执行框架,允许调度器通过对交易的重新执行进行确定性定价。
5.2 Levels of Determinism
因为交易的精确时间可能因节点而异,并行调度器在执行中引入了一定程度的非确定性。这与共识机制依赖于节点严格收敛到相同状态的要求直接冲突。因此区块链系统与传统算法相比,并行调度器必须保持更高水平的确定性。我们在乐观事务执行中定义了以下三个确定性级别:
Classic OCC: first-come-first-served 的执行方式。没有确定性保证,交易在执行完后立即提交,不考虑其在区块中的顺序,不同节点最终结果可能不一致。
OCC with deterministic commit order:交易的提交操作会延迟到区块中前一个交易提交后。这意味着不同节点上的最终执行结果将是相等的,即使实际执行顺序可能不同。通过严格按照块交易顺序提交,或者根据依赖图进行调度,可以满足这一要求。
OCC with deterministic aborts:交易只能看到在执行之前决定的状态版本(即使有更新的版本可用)。交易的每次执行都将在所有节点上提交或中止。虽然确定性顺序保证所有节点的可观察输出(结果状态)相同,但实际执行可能仍然不同:由于交易的时间不同,交易可能在一个节点上提交,而在另一个节点则中止。如果协议依赖于此提交/中止决定来惩罚中止并避免 DoS 攻击,这将导致不同的状态。所以我们的目标是中止本身具有确定性:如果交易在一个节点上中止一次,那么在所有其他节点上也会中止一次。
5.3 OCC-DA: OCC with Deterministic Aborts
我们的执行模型基于快照隔离(snapshot isolation)的 OCC。交易被安排在一组线程上执行,已执行的交易是根据块交易顺序提交的。在执行开始时,每个交易都会接收对应于存储版本的快照,此快照在交易执行过程中不会更改。
例如,假设交易 #1 已经被提交,交易 #2 正在一个线程上执行,而我们正在另一个线程调度交易 #3。在这种情况下,#3 可以看到存储版本 #1(直到并包括 #1 的写入的存储内容)。如果在 #3 的执行过程中,#2 修改了一些存储值,那么这些更新对 #3 来说是不可见的。如果在 #3 的提交期间,调度器检测到 #3 读取的一些值被 #2 同时修改,即 #3 对过时的值进行了操作,#3 将中止并被重新执行。
OCC-DA 定义如下:
在执行之前,我们为每个交易的每次执行分配一个存储版本(storage version):(𝑡𝑥𝑛,𝑖) → 𝑠𝑣𝑛,𝑖。(𝑡𝑥𝑛,𝑖) 代表 𝑖 次执行交易 #n,其中 𝑖 = 0, 1, 2, … 根据调度程序的实现,交易可以执行两次或多次。最后一次执行必须提交,而之前的所有执行都将中止。对于在执行单元中(例如在块中)的所有交易 #n 的所有可能的执行,𝑠𝑣𝑛,𝑖 在所有节点上统一定义,并且在执行之前进行定义,从而不受不确定性的执行影响。对于任何 (𝑡𝑥𝑛,𝑖), 交易 #n 将在所有节点上中止或提交。
在 (𝑡𝑥𝑛,𝑖) 执行过程中, 调度程序必须允许交易访问 𝑠𝑣𝑛,𝑖 之前且包括此交易写入的存储条目。调度程序不得允许交易访问由 id 高于 𝑠𝑣𝑛,𝑖 的交易写入的存储条目。如果 𝑠𝑣𝑛,𝑖 尚未提交,交易无法开始执行,必须等待。
5.4 Example
有 4 笔交易,标记为 #1 到 #4。#1 和 #3 存在存储冲突:#1 写入由 #3 读取的存储条目。然后,让我们在不同的决定论保证下,在两个不同的节点上调度这四个交易,每个节点有2个线程。
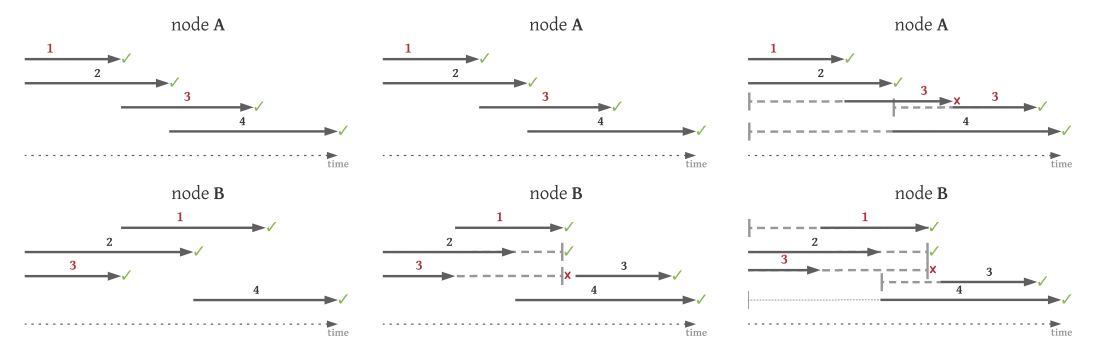
左图是使用经典 OCC 的调度示例。这种方法没有确定性的保证。特别地,我们可以看到节点 A 上的提交顺序是 #1-#2-#3-#4,而节点B上是 #3-#2-#1-#4。两个冲突交易的不同相对顺序(#1-#3,#3-#1)可能导致两个节点的状态不一致。虽然 #1 和 #3 冲突,但在本例中,它们不是同时执行的,因此都不需要中止。
中间的图中,我们看到了一个具有确定性提交顺序的 OCC 示例。在节点 B 上,#3 在 #1 之前完成执行,此时检测到冲突并中止 #3,直到 #1 完成之后才提交。节点 A 和 B 上的最终提交顺序是 #1-#2-#3-#4。由于 #1 和 #3 在两个节点上执行的相对顺序不同,#3 的第一次执行在节点 A 上提交,而在节点 B 上中止。在分布式共识中,这种不确定性是不可接受的。
右图显示了 OCC-DA 的工作原理。在执行之前,所有节点都决定 #3 的第一次执行只能读取 #1 执行之前的状态 (
𝑠𝑣3,0 := 0),而第二次执行可以看到 #2 之后的状态 (𝑠𝑣3,1 := 2)。因此,即使在节点 A 中 #3 被安排的 #1 之后,它无法获得 #1 的写入并将中止。这与节点 B 上 #3 与 #1 同时执行的结果一致。第二次执行 #3 将在节点 A 和 B 上获得最新状态,因此它将在两个节点上提交。
5.5 Assigning Storage Versions
依赖两种信息:
- 首先,我们可以使用交易的预期执行时间来查找交易预期读取的最新存储版本。假如 #3 将在 #1 之后但在 #2 之前开始执行,我们设置
𝑠𝑣3,0 := 1。 - 其次,我们通过对事务依赖关系图的估计来允许预防中止。例如,如果我们猜测 #3 可能与 #1 冲突,那么我们可以设置
𝑠𝑣3,0 >= 1。
存储版本分配的准确性直接影响并行调度程序的性能:如果我们使用的存储版本太低,那么我们就有可能引入更多的中止。如果我们使用的存储版本太高,那么交易可能需要一直等待存储版本可用,从而导致线程利用率不足。
5.6 The Algorithm
1 | |
该算法将一组交易及其依赖项作为输入。依赖图可以通过估计每个交易的读写集来构建。估计不一定是完美的,但它需要在所有区块链节点上具有确定性和一致性。它越精确,我们可能遇到的不必要中断就越少。
根据依赖关系图,每个交易的存储版本被初始化为它所依赖交易的最大 id,如果没有依赖关系,则为 −1。交易被加入最小堆 𝐻𝑡𝑥𝑠 并按存储版本索引。还有另外三个最小堆:𝐻𝑟𝑒𝑎𝑑𝑦 维护准备好被调度的交易,𝐻𝑡ℎ𝑟𝑒𝑎𝑑𝑠 是用于执行交易的线程池,𝐻𝑐𝑜𝑚𝑚𝑖𝑡 用于已完成执行并等待提交的交易。全局变量 𝑛𝑒𝑥𝑡 维护下一个要提交交易的 id。接下来:
Stage 1:将交易调度到线程池中。当与其存储版本对应的交易已提交时,我们认为该交易已准备好执行。如果线程池有空槽,交易将被推入线程池。
Stage 2:线程池中交易的执行。我们选择剩余 gas 最少的交易,即是 𝐻𝑡ℎ𝑟𝑒𝑎𝑑𝑠 的顶部元素,把它推入 𝐻𝑐𝑜𝑚𝑚𝑖𝑡。
Stage 3:逐个尝试提交在 𝐻𝑐𝑜𝑚𝑚𝑖𝑡 中的交易。𝐻𝑐𝑜𝑚𝑚𝑖𝑡 中的交易按照 id 的顺序进行维护,因为我们总是按顺序提交。对于每个交易,算法通过检查当前交易和自开始执行以来提交的交易之间是否存在读写冲突来判断中止或提交。如果中止,交易将被推回到 𝐻𝑡𝑥𝑠 其新存储版本设置为 𝑖𝑑 − 1。
6 EVALUATION
6.1 Experimental Setup
我们首先构建交易的依赖图,其中顶点(对应于交易)由消耗的 gas 加权。然后我们模拟在一组线程(2、4、8、16、32)上调度事务。
6.2 Assumptions and Limitations
我们的评估是基于使用真实数据的模拟,而不是基于在真实区块链系统中的实现。
6.3 Evaluation Results
略
7 THREATS TO VALIDITY
略
8 RELEVANCE AND FUTURE WORK
略
9 RELATED WORK
略
10 CONCLUSION
略