「毕」 7. 实验设计参考
本文最后更新于:5 个月前
参考几篇关于 Fabirc 改进论文的实验部分,来设计改进后系统的测试方法并进行测试。注:并未记录所有的实验,只是选取了对我的实验有帮助的部分进行了翻译。
1 Fabric [1]
引入了一个类似于 Bitcoin 的加密货币,称之为 Fabric Coin(Fabcoin)用于测试系统的性能。
Fabcoin 中的每个状态都是一个元组,形式为 (key, val) = (txid.j, (amount, owner, label)),表示作为交易的第 j 个输出创建的币状态,带有标识符 txid,并分配给具有公钥 owner 的实体的金额单位,带有标签 label。标签是用于识别给定类型币(例如,’USD’、’EUR’、’FBC’)的字符串。交易标识符是唯一标识每个 Fabric 交易的短值。Fabcoin 实现包括三个部分:(1)客户端钱包,(2)Fabcoin 链码,(3)用于 Fabcoin 实现其认可策略的自定义 VSCC。
1.1 实验环境
(1) 节点运行 Fabric 版本 v1.1.0-preview2,通过本地日志记录进行性能评估;(2) 节点托管在一个 IBM Cloud(SoftLayer)数据中心(DC)中,作为专用 VMs,通过 1 Gbps(名义上的)网络互连;(3) 所有节点都是 2.0 GHz 的 16-vCPU VMs,运行 Ubuntu,具有 8 GB 的 RAM 和 SSD 作为本地磁盘;(4) 单一通道排序服务运行一个典型的 Kafka 配置,包括 3 个 ZooKeeper 节点,4 个 Kafka 节点和 3 个 Fabric 排序者,都在不同的 VMs 上;(5) 总共有 5 个对等节点,都属于不同的组织(orgs)并且都是 Fabcoin 认可者;(6) 签名使用默认的 256 位 ECDSA 方案。为了测量和分析跨多个节点的交易流程中的延迟,节点时钟在整个实验过程中都与 NTP 服务同步。所有 Fabric 节点之间的通信都配置为使用 TLS。
在每个实验中,第一阶段我们调用仅包含 Fabcoin 铸币操作的交易来生成硬币,然后在实验的第二阶段中,我们调用 Fabcoin 花费操作来花费之前铸币的硬币(实际上运行单输入、单输出的花费交易)。在吞吐量测量时,我们使用越来越多的 Fabric CLI 客户端(经修改以发出并发请求)在单个 VM 上运行,直到端到端吞吐量饱和,并报告略低于饱和的吞吐量。吞吐量数字报告为实验稳定状态期间的平均值,不考虑“尾部”,在尾部一些客户端线程已经停止提交他们的交易。在每个实验中,客户端线程集体调用至少 500,000 次铸币和花费交易。
1.2 实验结果
1.2.1 区块大小的选择
对 0.5 MB 到 4 MB 不同的区块大小设置进行实验。
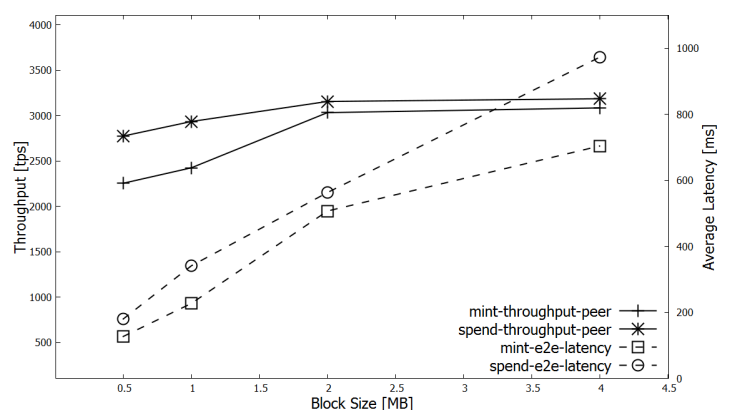
可以观察到吞吐量在区块到达 2 MB 后便没有显著增加了,反而延迟更差。因此,我们采用 2 MB 作为之后实验的块大小,以最大化测量的吞吐量为目标,假设大约 500 ms 的端到端延迟是可以接受的。
1.2.2 节点 CPU 的影响
Fabric 节点运行许多 CPU 密集型的加密操作。为了估算 CPU 性能对吞吐量的影响,我们进行了一组实验,在这些实验中,4 个节点分别运行在 4、8、16 和 32 个 vCPU VMs 上,同时进行了粗粒度的块验证延迟分级,以识别瓶颈。验证阶段,特别是 Fabcoin 的 VSCC 验证,由于涉及到大量数字签名验证,因此在计算上是密集的。我们通过在节点本地测量验证阶段的延迟来计算节点的验证吞吐量。
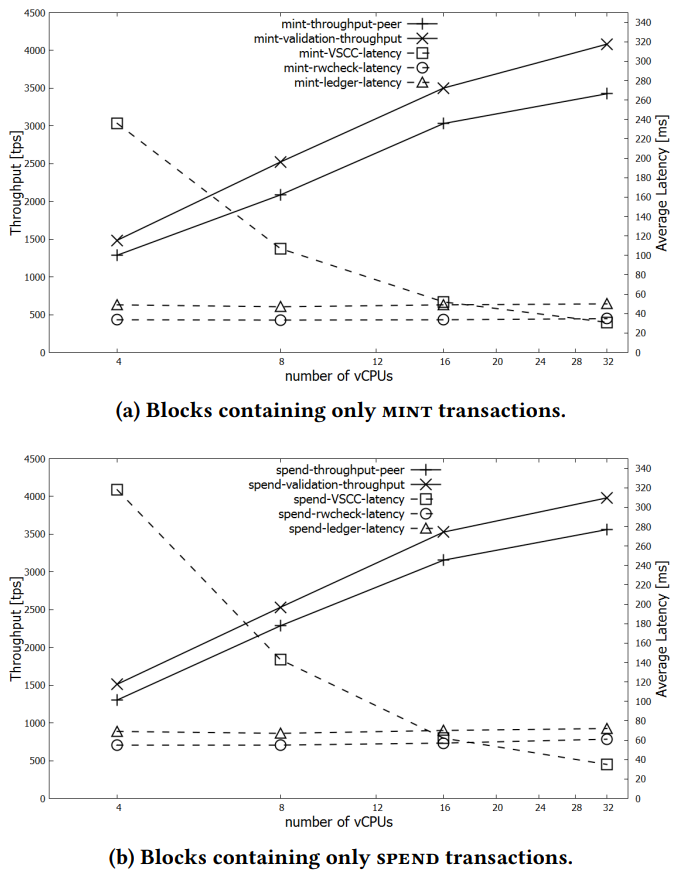
我们可以观察到,验证工作明显限制了吞吐量。此外,Fabcoin VSCC 的验证性能随着 CPU 增加几乎是线性的,因为 Fabric 的 VSCC 的背书策略验证是并行的。然而,读写检查和账本访问阶段是顺序的,随着核心数(vCPUs)增加,它们变得更加显著。这在花费交易中尤为明显,因为比铸币交易更多的花费交易可以放入 2 MB 的区块,这会延长顺序验证阶段的持续时间(即读写检查和账本访问)。
最后,在这个实验中,我们在拥有 32 个 vCPU 的节点上测量到每秒超过 3560 个 SPEND 交易的平均吞吐量。MINT 吞吐量一般略低于 SPEND 吞吐量,但差异在 10% 以内,32 个 vCPU 的节点达到了超过 3420 个 tps 的平均吞吐量。
1.2.3 阶段性的延迟分析
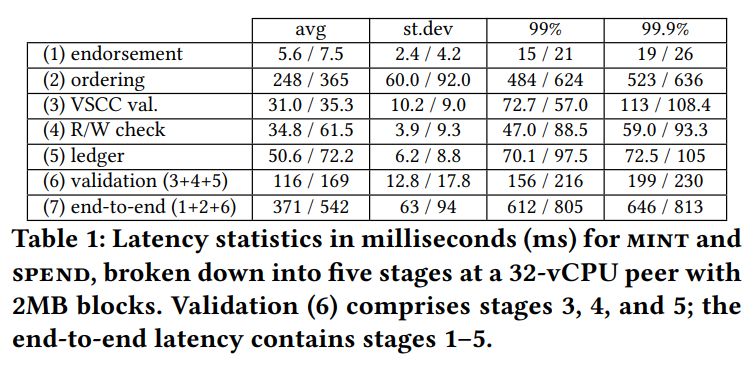
在之前的实验中,我们在报告的峰值吞吐量时进行了粗粒度的延迟分析。排序阶段包括广播传递延迟以及在验证开始之前的节点内部延迟。表格报告了铸币和花费的平均延迟、标准差和尾延迟。我们观察到排序阶段占据了整体延迟的主导地位。我们还看到平均延迟低于 550 毫秒,具有次秒级的尾延迟。特别是在我们的实验中,最高的端到端延迟来自于负载建立过程中的第一个区块。
2 Optimizing Fabric [2]
本文先是对 Fabric 1.0 进行了测试,总结并优化了其中的几个性能瓶颈,测试部分见我之前翻译的文章。
注:此论文的三个优化已经被 Fabric 1.1 采用。
3 FastFabric [3]
3.1 实验环境
我们使用了一台 1 Gbit/s 交换机连接的十五台本地服务器。每台服务器配备了两个 2.10 GHz 的 Intel Xeon CPU E5-2620 v2 处理器,总共提供 24 个硬件线程和 64 GB 的 RAM。我们使用 Fabric 1.2 作为基准,并逐步添加我们的改进以进行比较。默认情况下,Fabric 配置为使用 LevelDB 作为对等方状态数据库,排序节点将已完成的区块存储在内存中,而不是在磁盘上。此外,我们在不使用 Docker 容器的情况下运行整个系统,以避免额外的开销。
我们确保实现不会改变 Fabric 的验证行为,所有测试都是使用不冲突和有效的交易进行的。这是因为有效的交易必须通过每个验证检查步骤,并且它们的写入集将在提交期间应用于状态数据库。相比之下,无效的交易可以被丢弃。因此,我们的结果评估了最坏情况下的性能。
在实验中,我们专门关注排序者或提交者时,会隔离相应的系统部分。在排序者实验中,我们从客户端向排序者发送预加载的已认可交易,而模拟的提交者会简单地丢弃已创建的区块。同样,在提交者的基准测试期间,我们将预加载的区块发送给提交者,并创建模拟的认可方和区块存储,它们会丢弃已验证的区块。
然后,在端到端设置中,我们实现了完整的系统:
- 背书节点根据提交者已验证的区块的复制世界状态认可客户端的交易提案;
- 排序者从已认可的交易创建区块并将其发送给提交者;
- 提交者验证并提交更改到其内存中的世界状态,并将已验证的区块发送给背书节点和区块存储;
- 区块存储使用 Fabric 1.2 数据管理来将区块存储在其文件系统中,将状态存储在 LevelDB 中。
为了进行公平比较,我们在所有实验中使用相同的交易链码:每个交易模拟从一个帐户向另一个帐户的资金转移,读取并修改状态数据库中的两个键。此外,我们使用默认的背书策略,即接受单个背书方签名。
3.2 实验结果
实验结果见此文章。
在最后端到端的测量中,我们设置了单一的排序节点,它使用三个 ZooKeeper 服务器和三个 Kafka 服务器的集群,具有默认的主题复制因子为三,并将其连接到一个对等节点。来自此对等节点的区块被发送到一个单一的数据存储服务器,该服务器将世界状态存储在 LevelDB 中,将区块存储在文件系统中。为了进行横向扩展,五个背书节点复制对等方状态并提供足够的吞吐量来处理客户端背书负载。最后,客户端安装在自己的服务器上;此客户端从五个背书节点服务器请求背书,然后将已背书的交易发送到排序服务。在我们的本地数据中心,总共使用了连接到相同 1 Gbit/s 交换机的十五台服务器。

我们从客户端发送了共计 100,000 笔已背书的交易给排序节点,排序节点将它们分成每个块包含 100 笔交易的区块,并将它们传递给对等节点。为了估算吞吐量,我们测量了对等节点上提交的区块之间的时间,并对单次运行的平均时间进行了测量。这些运行重复了 100 次。表格显示相对于 Fabric 1.2 基准测试,吞吐量有了显著的 6-7 倍的改进。
4 Fabric++ [4]
提出了 reorder 和 early abort 两种优化方案。集群由六台相同的服务器组成,这些服务器位于同一机架内,并通过千兆以太网连接。其中四台机器充当对等节点,一台机器运行排序服务,而另一台机器充当客户端,负责提交交易提案。每台服务器都由两颗四核的 Intel Xeon CPU E5-2407(SandyBridge 架构)组成,主频为 2.2 GHz,拥有 32 KB 的 L1 缓存,256 KB 的 L2 缓存以及 10 MB 的共享 L3 缓存。每个 NUMA 区域都连接有 24 GB 的 DDR3 内存。操作系统采用的是 64 位的 Arch Linux,内核版本为 4.17。Fabric 被设置为使用 LevelDB 作为当前状态数据库。
4.1 实验环境
4.2.1 Throughput under Smallbank
选择交易:根据概率 Pw,以均匀方式从五个修改交易中选择一个要执行的交易,或者以概率 1-Pw 选择读取交易。这意味着修改交易和读取交易之间的选择是随机的,并且概率 Pw 控制了执行修改交易的频率。
确定账户:对于每个选中的交易,通过遵循 Zipf 分布来确定要访问的账户。Zipf 分布的偏斜度可以通过设置 s 值来调整。如果 s 值为 0,分布将是均匀的,而较高的 s 值将导致分布更加偏斜,即更倾向于访问一小部分账户。

4.2.2 Throughput under custom workload
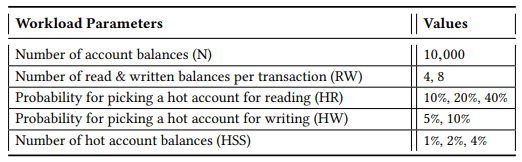
工作负载完全由一个高度可配置的交易组成,该交易对一组账户余额执行一定数量的读取和写入访问。初始时,我们创建了一定数量的账户(N),每个账户都初始化为一个随机整数。我们的交易在这些账户的子集上执行一定数量的读取和写入操作(RW)。在这些账户中,存在一定数量的热门账户(HSS),它们以更高的概率被选中进行读取或写入访问。选择用于读取的热门账户的概率(HR)和选择用于写入的热门账户的概率(HW)也可以进行配置。
4.2 实验结果
实验结果见此文章。
Caliper 在高交易触发率下表现不佳,我们以每个客户端每秒 150 次的较低速率触发交易,总共每秒触发 600 次交易。将区块大小调整为 512 次交易。使用 N = 10,000、RW = 4、HR = 40%、HW = 10%、HSS = 1% 来测试我们的自定义工作负载。
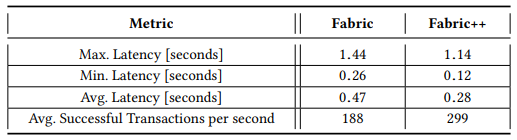
5 FabricSharp [5]
实验结果见此文章。
6 参考文献
[1] Androulaki E , Barger A , Bortnikov V , et al. Hyperledger fabric: a distributed operating system for permissioned blockchains[C]// European Conference on Computer Systems.ACM, 2018.
[2] Nathan S , Thakkar P , Vishwanathan B . Performance Benchmarking and Optimizing Hyperledger Fabric Blockchain Platform: IEEE, 10.1109/MASCOTS.2018.00034[P]. 2018.
[3] Gorenflo C , Lee S , Golab L , et al. FastFabric: Scaling Hyperledger Fabric to 20,000 Transactions per Second[J]. IEEE, 2019.
[4] Sharma A , Schuhknecht F M , Agrawal D , et al. Blurring the Lines between Blockchains and Database Systems: the Case of Hyperledger Fabric[C]// ACM SIGMOD 2019. ACM, 2019.
[5] Ruan P , Loghin D , Ta Q T , et al. A Transactional Perspective on Execute-order-validate Blockchains[J]. 2020.