「毕」 8. 毕业论文(精简版)
本文最后更新于:1 个月前
题目:《对于 Execute-Order-Validate 区块链高并发冲突问题的优化》
发表:https://zte.magtechjournal.com/EN/10.12142/ZTECOM.202402004
Abstract
伴随着区块链技术的成熟与进步,一种新型的 Execute-Order-Validate(EOV)区块链架构被提出,使得交易在执行阶段可以并行。这一架构的代表系统便是 Hyperledger Fabric。但是由于其的并行执行机制,在验证阶段可能会产生大量的 MVCC 冲突,导致大量交易被无效化。根据产生原因不同,我们将冲突分为区块内冲突和区块间冲突两种类型,并基于 Fabric v2.4 实现了优化方案 FabricMan。针对区块内冲突,我们在排序阶段设计了一个重排序算法来提高交易成功率,并根据交易依赖图实现了验证阶段的并行验证。我们还对同一区块内简单的资产转移交易实现了交易的合并,使其不会触发多次版本检验。针对区块间冲突,我们实现了一个基于缓存的版本验证机制,来提前检测并中止无效交易。我们将 FabricMan 与 Fabric 和 Fabric++ 两个系统进行了实验对比,结果表明在吞吐量、交易中止率、算法执行时间等多项实验指标上,FabricMan 均优于对比系统。
1 Introduction
区块链技术的流行开始于比特币[1]论文的发表,其本质上是一种分布式账本技术,而这种技术受欢迎的真正原因在于它提供了一种方式,使得在缺少可信第三方条件下的点对点交易变为可能。伴随着以太坊[2]中智能合约的出现,区块链技术凭借其去中心化、防篡改、可溯源等特性,被研究和应用在金融[3]、医疗[4,5]、供应链[6]和物联网[7]等多个领域。
从参与者的角度,区块链系统可以分为许可链和非许可链。非许可链又叫公链,是任意节点都可以匿名参与的区块链。由于节点身份未知,且相互不信任,这类区块链系统中往往会使用 proof of work 或其他共识机制来解决拜占庭容错共识问题[8]。而另一方面,许可链是由一组身份经过验证的节点组成的区块链系统。这类系统往往只应用于某些特定的场景,其中的节点虽然并不完全信任彼此但拥有共同的目标。许可链对参与节点进行约束,并且可以控制不同节点的读写权限,因此更加适用于企业级的应用。
然而,不论是像比特币、以太坊这样的非许可链还是像 Tendermint、Quorum 这样的许可链,大部分主流的区块链系统使用的都是 active replication[9]:首先通过共识协议或者 atomic broadcast 对交易进行排序,并打包成区块传递给节点;然后所有节点按照顺序执行交易,改变自己的账本状态。我们将这种系统叫做 OE(Order-Execute)architecture,该模型的局限性在于所有节点都必须按顺序串行执行所有交易,这无疑会限制系统的吞吐量。为了让交易的执行有更好的并行性,一种新型的 EOV(Execute-Order-Validate)模型被提了出来:在执行阶段,客户端会把交易提案发送给多个节点进行背书,此时进行背书的节点仅仅是区块链网络中节点的一个子集,不同的节点在同一时间可以对不同的交易进行背书,从而该系统拥有并行执行交易的能力。收集到足够数量的背书后,客户端会将所有背书响应打包成一笔交易发送给排序节点进行排序并出块。最后排序节点将区块发送给所有节点来验证并同步账本状态。该模型使用乐观的多版本并发控制技术来保证并行执行数据的一致性,随之而来的问题是验证阶段可能会出现的 MVCC(Multi-Version Concurrency Control)[10]冲突。
我们将 EOV 系统中的冲突分为两类,一是区块内读写冲突 (within-block conflicts),即在同一个区块内先执行交易的写集更改了后面某一笔交易读集的版本号,使得后一笔交易在验证阶段无效。二是跨区块读写冲突 (cross-block conflicts),即某一笔交易在执行阶段读的值,在到达验证阶段之前,被这期间提交的其他区块修改所导致的最终无效化。Ankur[11] 等人提出了一个名为 Fabric++ 的系统,通过对交易重排序来改善区块内读写冲突的问题,使得最终被无效的交易数量减少。但是经我们测试,该算法在交易冲突率较高时效率很低。为改善上述问题,我们以 Fabric v2.4 作为基础对 EOV 区块链系统做了几点优化,并将系统命名为 FabricMan。本文的主要贡献如下:
- 我们设计并实现了一个时间复杂度较稳定的重排序算法来减少区块内的读写冲突,并设计实验与 Fabric++ 的算法相比较,发现在交易冲突率较高的情况下我们的算法更优秀。
- 基于重排序时生成的交易冲突图,我们在验证阶段对无关交易进行并行验证,以此发挥出多核 cpu 的优势。
- 在链码参数层面分析交易,我们对简单的资产转移交易进行合并,使得多笔交易在验证阶段只用验证一次读写集,最大化该类型交易的验证通过率。
- 我们实现了一个基于缓存的版本验证机制,在排序阶段提前检测并中止了部分无效交易,来减少跨区块的读写冲突。
The rest of the paper is organized as follows: 第 2 章会介绍 Hyperledger Fabric 的结构以及其他的相关研究,第 3 章会对 Fabric 中存在的问题进行理论分析并提出解决思路,第 4 章会介绍 FabricMan 的设计和优化点,第 5 章对 FabricMan 的优化进行实验测试,并分别与 Fabric 和 Fabric++ 对比,最后第 6 章对我们的工作进行总结。
2 Background and Related Work
2.1 EOV Architecture in Hyperledger Fabric
基于 EOV 架构模块化设计区块链的代表之一便是 Hyperledger Fabric[12],简称 Fabric。Fabric 中的所有节点在任何时候都是已知并经过授权的,主要分为三种类型:(1) client 节点负责提交交易提案(transaction proposals),并收集背书响应;(2) peer 节点负责 executes 和 validates 交易提案,并 commits 其读写集以维护本地的账本。不同的 peer 节点被划分到不同的 organizations,同一组织内的 peer 相互可信;(3) orderer 负责对接收到的交易进行排序,并按照预设的规则出块。区块中的交易顺序是由所有 orderer 节点基于共识协议共同决定的。系统中的交易流程如 Figure 1 所示,The workflow of a transaction consists of three phases: execution, ordering, and validation.
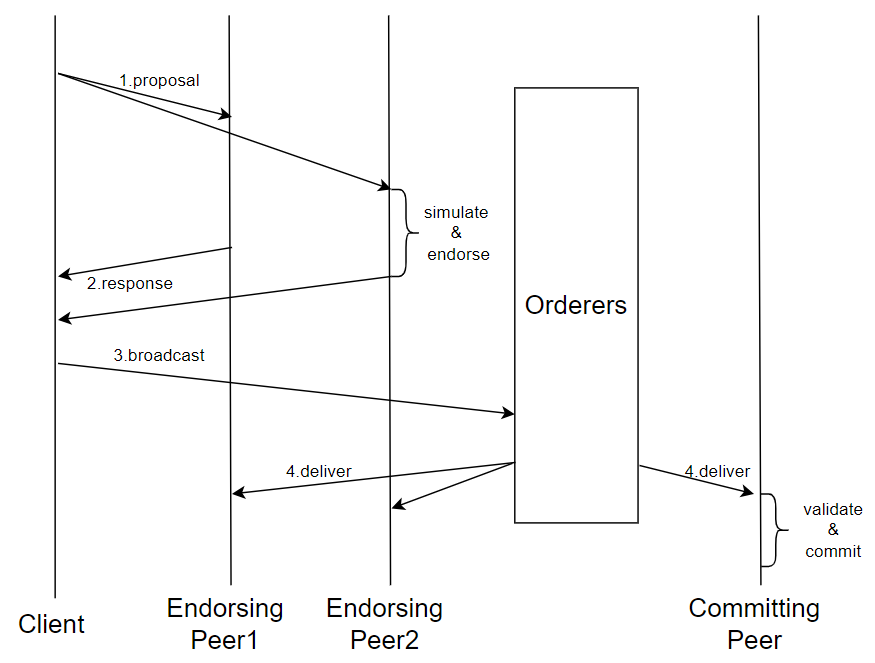
2.1.1 Execution Phase
在执行阶段,客户端会按照提前设定好的背书政策(endorsement policy)将交易提案发送给 peer 节点的一个子集,called the endorsers。由于参与交易的多个组织之间是互不信任的,通常背书政策需要每个组织至少有一个 endorser 参与背书。endorsers 会按照本地维护的当前账本状态并行的模拟执行交易,并生成相应的读写集。这里的读集是一个(key,ver)二元组,写集是一个(key,val)二元组,这里的 key is a unique name representing the entry,ver 和 val 分别是实体最新的版本号(由最近更新此实体的区块高度和交易号表示)和值。执行完成后,endorsers 会将读写集与自己的签名返回给 client,当 client 收集到足够数量的来自不同 endorsers 的相同读写集时,便可以将它们打包成一笔交易发送给排序集合,来进入下一个阶段。
2.1.2 Ordering Phase
在排序阶段,不同的 orderers 会不断从不同的 clients 接受交易。ordering service 需要达成两个目标:(a) 对交易顺序达成共识,(b) 将排好序的交易按照规则打包成区块并 deliver 给所有的 peers。Fabric v2.4 在 (a) 中使用的是 Raft[6] 协议,for achieving crash-fault-tolerant consensus。而 (b) 中的出块规则一般由最大出块间隔和区块包含最大交易数量共同形成。注意,系统并不保证所有节点会同时收到区块,但是可以确定所有节点收到的区块中的交易顺序是相同的。
2.1.3 Validation Phase
当节点收到来自 orderers 的一个区块时,首先检测是否有 orderers 的签名以及区块结构的合法性,若通过检测则将区块加入一个验证队列,保证其可以加入区块链,然后依次进入 VSCC 和 MVCC 验证阶段。在 VSCC 阶段,节点会检查区块中每一笔交易的签名是否满足该链码特定的背书策略。若不满足,则将该交易标记为无效但依旧留在块中。在 MVCC 阶段,会按顺序对所有标记为有效的交易进行 Multi-Version Concurrency Control check。如果交易读集中某个 key 的版本号与当前世界状态中的版本号不一致,交易将会被标记无效。最后节点将区块写入本地账本,并根据每一笔交易的有效性修改当前世界状态。
2.2 Optimization of Fabric++
The vanilla Fabric 是按照交易抵达排序节点的先后顺序来确定区块内的交易顺序的,这样虽然可以快速进行排序,但同时可能导致潜在的不必要的序列化冲突。如 Table 1 所示,四笔交易按照 T1,T2,T3,T4 的顺序排列出块,T1 首先将 k1 的版本从 v1 更新至 v2。由于 T2、T3、T4 都需要读取 v1 版本的 k1,它们在验证阶段都会因为读取过时的版本被标记为无效,最终区块只会有一笔有效交易。被无效的交易若想被重新执行,则又需要通过新一轮的 simulation, ordering, and validation,这无疑大大降低了系统的效率。

Ankur 等人对上述问题提出了一个名为 Fabric++ 的优化系统。他们发现之前例子中的四笔交易是存在一个无冲突排序的,即 T4,T2,T3,T1 如 Table 2 所示。导致区块产生冲突的原因是 Fabric 按照交易到达顺序进行排序。所以他们在 Fabric 的基础上增加了一个重排序算法,根据交易间读写集的关系来提前中止少量交易,并为剩余交易构建一个无冲突排序,以此来增加区块内的交易成功率。

Fabric++ 的重排序算法主要分为五个步骤:(1)首先根据所有待排序交易的读写集构建冲突图。(2)然后应用 Tarjan[13] 的算法来识别所有强连通子图,并使用 Johnson[14] 的算法识别强连通子图中的所有环。(3)识别每一笔交易所在的环,并分别统计出现在多少个环中。(4)依次中止出现在最多环中的交易,直到冲突图无环。(5)最后利用剩余的交易建立一个可序列化的调度方案。
2.3 Related Work
目前对于 EOV 区块链的研究主要有性能测试[15-19]、安全性分析[20-23]、性能优化几个方向,本文主要关注对性能的优化。优化主要可以分为两类:(1)提升系统整体的吞吐量。(2)减少并行执行所带来的读写冲突。
Parth Thakkar[24] 等人通过配置 Block Size、Endorsement Policy、Channel、Resource Allocation、Ledger Database 等五个参数,对 Fabric v1.0 系统性能进行了较为全面的测试,并发现了其三个主要的性能瓶颈:(1)背书策略的验证。(2)块中交易的顺序策略验证。(3) CouchDB 的状态验证和提交。同时他们对上述问题进行了简单的优化:(1)使用以序列化形式为键的哈希映射来缓存反序列化的身份,以此减少加密操作的资源消耗。(2)并行验证多个交易的背书,以利用闲置的 CPU 并提高整体性能。(3)对于 CouchDB 的批量读写优化。达到了提升系统整体吞吐量的效果。
Christian Gorenflo[25] 等人重新构建了 Hyperledger Fabric v1.2。通过(1)在排序时仅传入交易 ID 而非整个交易。(2)在 committers 中积极缓存未组装的块,同时并行化尽可能多的验证步骤。(3)重新设计数据管理层,使用内存数据库取代原有数据存储。(4)分离负责背书和提交的节点角色。以此减少交易排序和验证期间的计算和 I/O 开销,将交易吞吐量从每秒 3000 笔提高到 20000 笔。
Pingcheng Ruan[26] 等人研究了 Fabric++ 的方案,认为其没有考虑到跨区快交易之间的依赖性,重排序效果受限。他们提出了一种更细粒度并发控制策略下的重排序算法,并验证了其安全性,使得重排序效果得到提升。
Qiucheng Sun[27] 等人分析了 Fabric++ 实现的重排序算法,在信任方面发现问题。并基于贪心算法提出了一个可信的重排序算法。
3 Problem Analysis
In this section,我们主要介绍 EOV 架构中存在的两种 MVCC 冲突,namely within-block conflicts and cross-block conflicts,并分析产生这两种冲突的原因,同时提出我们的发现与改进思路。
正如在第 2 章所提到的,Fabric 在执行阶段会生成交易的读写集。其中读集包含该交易读取的所有 key 的列表,以及相应的 version number。写集包含最终用于更新账本的键值对。在验证阶段,节点会根据本地数据库的当前状态对交易的读写集做 MVCC 验证。验证方法就是检测读集中的版本号是否与本地当前状态的版本号一致。若版本不一致,交易会被标记为无效,其写集无法被用于更新账本状态,此时便发生了 MVCC 冲突。为了检测这一冲突对系统带来的影响,我们在第 5 章描述的环境配置下,使用 SmallBank 智能合约在 Fabric v2.4 上进行了测试。我们改变合约中账户数量,从 3000 到 500,并使用已有帐户随机触发 Smallbank 合约中的交易,记录其有效以及中止交易的 TPS 如 Figure 2 所示。
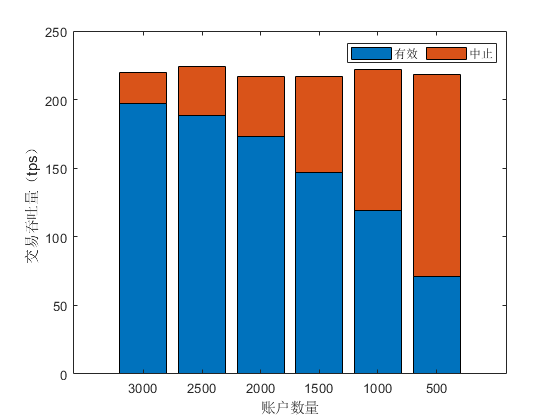
实验中每个区块约包含 256 笔交易,当总的账户数量为 3000 时,从中随机选择账户进行交易的冲突率较低,此时成功交易的 TPS 较高,约占 90%。当系统中账户数量减少时,区内交易冲突率升高,被中止的交易占比增加。在总账户数量为 500 时,成功交易的 TPS 仅有 30%。可见在区块内交易冲突数量增加时,系统性能下降显著。
在高并发执行环境中,我们将 EOV 区块链中 MVCC 冲突分为两种:within-block conflicts and cross-block conflicts。
3.1 Within-block Conflicts
Within-block conflicts 是发生在同一个区块不同交易之间的读写冲突。在构建区块时,如果将多个对同一个 key 进行读写的交易划分到同一区块中,就可能导致这一冲突。例如在 Table 3 的例子中,T1 、T2 按顺序被打包到一个区块中。在验证阶段,T1 先对 k1 进行了更新操作,使其版本号变为 v1。接下来轮到 T2 被验证,它的读集中包含 v0 版本的 k1,在进行 MVCC 验证时发现 v0 ≠ v1,所以 T2 被标记为无效。

Observation 1: 可以修改区块内交易的验证顺序,来减少区块内交易的冲突数量。块内冲突的根本原因是同一区块中两笔不同的交易对某个 key 进行了先写后读的操作,导致后一笔交易在验证读集时发生版本冲突。我们发现此例中若先验证 T2,将 k2 的版本进行修改,只读 k1 并不修改其版本,在后续验证 T1 时便不会产生冲突,这样两笔交易就可以同时通过验证提交到账本。
在 2.2 节中提到的 Fabric++ 在排序阶段使用了重排序算法,但是其在从强连通子图中检测所有的环时使用了 Johnson 的算法,这一算法的时间复杂度为 O((n+e)(c+1)),其中 n 是节点数量,e 是边的数量,c 是图中环的数量。冲突图中节点和边的数量受图大小的限制,可以控制在较小的值。但是环的数量却没有限制,可能非常大。文章[28]也指出了类似的问题:Fabric++ 在解决环时,每删除一个交易都需要重新计算循环中单个事务的出现次数,这使得整个算法的时间复杂度来到 O(n^3)。由于拓扑排序是图论中一种对有向无环图(DAG)进行顶点线性排序的算法,并且其算法执行时间非常稳定为 O(n+e),我们可以基于拓扑排序提出一种新的重排序算法,使得在交易冲突率较高的环境下系统依旧可以较快的完成重排序。
Observation 2: 交易重排序生成的冲突图可以体现交易之间的依赖信息,这一信息可以用于实现交易的并行验证。在 Fabric 区块链中,验证部分可以分为两个主要阶段:VSCC 和 MVCC。VSCC 用于评估交易中的背书是否符合链码指定的背书政策,由于交易背书的验证之间是相互独立的,这一步在 Fabric 系统中已经实现了并行。而 MVCC 用于确保在背书阶段交易期间读取的 key 的版本与提交时节点账本中的当前状态相同,这一步是在通过 VSCC 检测的交易上按顺序执行的。文章[24]指出 Fabric 的性能瓶颈之一是验证阶段对区块内所有交易的串行 MVCC 验证,如果能够利用交易之间的依赖性将无关交易并行验证,那么就可以充分利用多核 CPU 的优势以提升系统的性能。
Observation 3: 转账交易是测试中的主要交易类型之一,并且其逻辑简单、参数固定,适于合并。由于 Fabric 作为联盟链较难获取公开的区块数据,且不同用户搭建的链之间数据不互通,难以获取具有统计意义的数据,在此引用文章[29]对以太坊的交易分析。该文章对以太坊上一段时间内的交易进行并行执行,发现发生冲突的主要三种交易类型为:ERC20 代币交易占 60%,去中心化金融(DeFi)交易占 29%,游戏和收藏品交易占 10%。因此我们认为对转账交易之间的合并具有一定意义。我们希望通过合并其读写集的方式将转账交易进行合并,避免转账交易之间的冲突,以此提升此种类型交易的吞吐量。
3.2 Cross-block Conflicts
Cross-block conflicts 是发生在不同区块之间的读写冲突。由于 Execute-Order-Validate 的结构特性,交易在 simulated execution 和 verifcation submission 之间有一定的时延。如果有两笔交易在两个不同的区块中,在前一个区块进行验证之前,后一个区块中的交易读取了前一个区块中某笔交易写的 key,从而导致后一个区块中发生脏读,最终引起 MVCC 冲突。如 Figure 3 所示,T1 和 T2 是处在不同区块中的两笔交易。在执行交易时,T1 读取 k1 的当前版本号 v0 并加入其读集。从验证阶段可以看出 T1 的写集对 k1 进行了修改,但由于这一步是模拟执行,执行结果并不会更改数据库状态,所以紧随其后的 T2 执行阶段读取到的依旧是 v0 版本的 k1。之后包含 T1 的区块先进入验证阶段,并更新了节点当前状态中 k1 的版本号到 v1。当验证包含 T2 的区块时,节点就会检测出 T2 的读集中存在 k1 的版本冲突,从而导致交易无效。
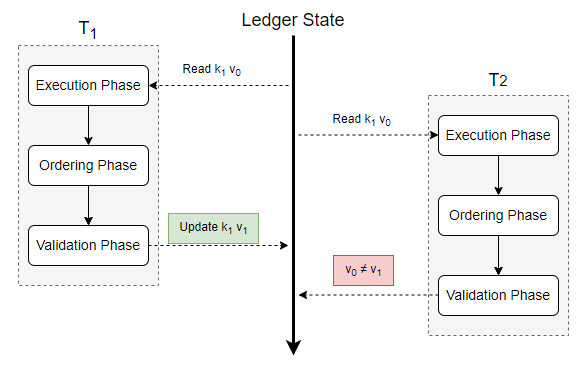
此外,在网络拥堵等特殊情况下也会产生区块间冲突。例如一笔交易 T1 读取了 v0 版本的 k1,但是在网络拥堵的环境下,T1 花费很长时间才到达排序节点并进入新的区块。但在此之前排序节点已经处理过高于 v0 版本的 k1 的交易 T2。注定无法通过 MVCC 验证的 T1,却依旧需要经历排序、出块和验证阶段,直到最后在验证交易读写集的版本时才会将其中止。
Observation 4: 排序节点有机会提前中止区块间冲突产生的无效交易。所有交易都会到达排序节点进行出块,由于交易读集中 key 的版本号都是在交易模拟执行时从账本中读取的,所以此时账本中该 key 的版本号一定不低于读集中的版本。所以如果当前区块中或节点后续收到的某个交易读集中的 key 低于此版本,则可以直接判定为无效交易。
4 Design of FabricMan
In the previous section,我们分析了 EOV 区块链中的区块内和区块间两种冲突问题,并发现了四个可以优化的方向。本章首先介绍我们对排序阶段流程的修改,之后介绍我们针对四个优化方向分别设计的交易重排序、并行验证、交易合并和缓存机制四个模块。
我们对 EOV 区块链的修改主要集中在排序阶段,如 Figure 4 所示。排序节点从多个不同的客户端接受交易,并按照交易到达的顺序将其加入一个 batch 数组,直到满足出块条件。出块条件由两部分组成:一是 batch 中交易数量到达设定的阈值,二是构建 batch 的时间到达设置的最大出块时间。满足其中任何一个条件的 batch 将不再加入新的交易,而是进入下一步的处理,新到达排序节点的交易会加入一个新创建的 batch。
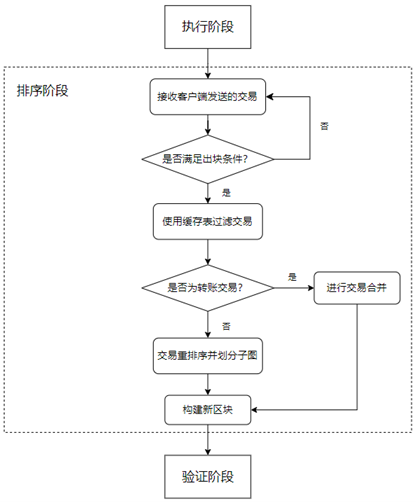
对满足出块条件的 batch,本系统首先通过排序节点维护的版本缓存表对 batch 中的所有交易进行过滤,在此期间系统会读取交易的读写集并与缓存进行比较。若不符合判定规则,系统会中止该交易并反馈给客户端。若通过缓存表过滤,系统会判断交易是否为转账交易,若是,则将其移动到转账交易数组,并与其他转账交易合并。最终 batch 中剩余的交易都是通过缓存过滤的非转账交易,系统会对它们进行重排序,中止冲突交易,并根据依赖关系划分交易子图。最后系统会使用合并交易、转账交易和重排序后的 batch 构建新的区块,将交易子图添加进区块头部,然后将区块发送给所有对等节点。
4.1 Transaction Reordering
在对一个交易集合 S 进行重排序时,首先需要识别交易间的依赖关系,来构建交易冲突图。在冲突图中,如果一笔交易 Ti 指向另一笔交易 Tj,则表示 Ti 的写集与 Tj 的读集有交集,记为 Ti → Tj。这表示在排序出块时,Tj 需要在 Ti 之前,否则 Tj 会因为读取过时的版本而被无效。在构建冲突图时,每一个节点代表一笔交易,由上述定义可知一个节点的出度表示该交易会影响多少个交易的有效性,入度表示受到多少其他交易的影响。此外,构建无冲突排序需要解决的一个重要问题就是图中出现的环。有环的图是无法进行序列化排序的,这需要我们在算法中移除一些交易来使原本的冲突图变为无环图。
我们的算法是基于拓扑排序的,但是由于拓扑排序无法适用于有环的图,所以我们做了一些改进。From a high-level perspective,算法主要分为五个步骤:(1)首先根据交易集合 S 中每一笔交易的读写集构建冲突图,并记录每个节点的入度和出度。(2)选择一个入度最小的节点作为待处理节点,若有多个节点满足条件,则选择一个出度最大的节点,若仍有多个则任选其中一个节点。(3)将指向待处理节点的其他节点从图中移除,直到待处理节点的入度为 0。(4)将待处理节点加入排序队列并从图中移除。(5)重复上述(2)(3)(4)步直到冲突图中无剩余节点。最后将排序队列进行反序,便可以得到一个无冲突的序列化排序。The pseudo-code of Algorithm 1 implements these five steps。注意在步骤 (2) 中,由于需要将待处理节点的入度变为 0,所以我们优先选择入度最小的节点,以留下更多的交易。又因为节点的出度是其在排序后会影响的交易数量,而最终排序是排序队列的反序,即在算法中先进入排序队列的交易会在较后的位置。所以我们优先选择出度最大的交易进行排序。
1 | |
为了理解算法中的实现细节,我们举一个例子。假设交易集合 S 中有 T0 到 T5 六笔交易,通过 Step(1) 根据交易读写集构建出的冲突图如 Figure 5 所示,每个节点的入度和出度如 Table 4 所示。由 Step(2),我们选择 T5 作为 nodeToSort,因为它此时是集合 S 中入度最小的节点。由于它的入度为 0 所以跳过 Step(3)。Step(4) 会将 T5 加入 result 队列,并将其从集合 S 中删除,然后将它指向的 T2 节点的入度减一。
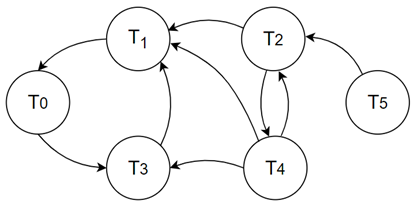
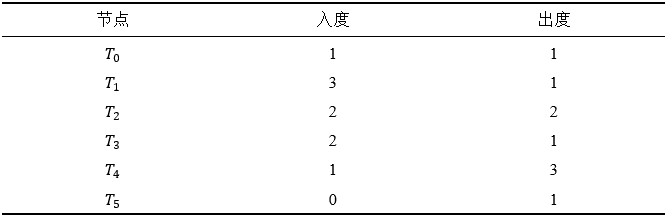
进入下一个循环,此时我们发现 T0、T2、T4 的入度都是 1,均为此时入度最小的节点,但是 T4 有最大的出度。根据 Step(2) 我们选择 T4 作为 nodeToSort。然后 Step(3) 从 S 中删除指向 T4 的节点 T2,使得 T4 的入度为 0,此时的冲突图如 Figure 6 所示,点的入度和出度如 Table 5 所示。Step(4) 将 T4 加入 result 队列,并将其从集合 S 中删除,然后将 T1 和 T3 的入度分别减一。
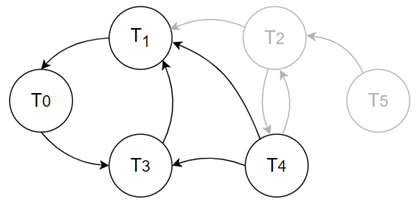
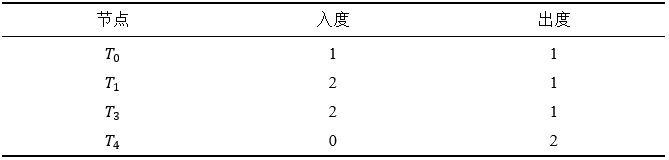
此时图中只剩下一个由 T0、T1、T3 组成的环,由于其入度出度都一样,我们选择 T0 作为 nodeToSort,移除 T1,将 T0 加入 result 队列,最后将 T3 加入 result 队列。将 result 队列反序,我们便得到了最终的重排序结果,即 T3、T0、T4、T5。此排序过程主体部分与拓扑排序时间复杂度相当,为 O(n+e),并且该算法并不受到图中环的数量影响,消除了 Fabric++ 算法中的这一缺陷。值得一提的是,我们的算法并不保证中止图中最少数量的交易使图无环,因为这是一个 NP 难的问题。我们只是提供了一个非常轻量级的方式来中止少量交易,从而生成一个可序列化排序方案。
4.2 Parallel Verification
在进行交易重排序时,算法会生成交易之间的冲突图,如 Algorithm 1 的 3、4 行所示,其中 cg 是生成的冲突图,由一个二维数组表示,cg[i] 是一维数组,若其中有一个元素 j 则表示 Tj 必须出现在 Ti 之前,即 Ti→Tj。而 incg 是 cg 的逆图,同样用二维数组表示,若 incg[i] 中有一个元素 j 则表示 Tj 必须出现在 Ti 之后,即 Tj→Ti。
在重排序完成后,系统会将算法中止的交易从冲突图中删除,最终剩下 cg’ 和 incg’ 两个无环子图,然后对其进行 DFS(深度优先遍历)操作来寻找子图中的连通分量,并进一步划分为相互不连通的子图,伪代码如表所示。
1 | |
系统得到存储子图信息的 components 数组后,对其进行序列化处理并在出块时将其放入区块头部。在验证阶段节点会对其进行反序列化操作,然后根据数组信息对独立的交易子图调用 Goroutine 并行完成后续 MVCC 验证操作。
4.3 Transaction Merging
假设有三个账户 A、B、C 的初始余额都为 10,初始版本都是 v0。在进行简单的转账交易时,有两笔交易 T1(A 给 B 转账 10 个数字货币)和 T2(B 给 C 转账 10 个数字货币),并且被打包到 Fabric 的同一区块中,读写集如 Table 6 所示。由于 T1 和 T2 都对 B 进行了读写,所以在 Fabric 中只有排序在前的一笔交易可以通过验证。

我们通过在背书阶段模拟执行时对交易链码的参数和读写集进行分析,来标记简单的转账交易,并在交易读集的结构体中加入 Value 字段用于表示其初始值。在排序阶段,节点会识别不同链码下的转账交易,并对同一链码的转账交易构建转帐表。首先节点会将账户的初始余额加入 moneyMap 表中,并将其对应的版本号加入 versionMap 表。然后对每一笔转账交易进行处理:若发起转账的账户余额小于转账金额,则直接将交易中止;若余额足够则将发送方余额减去转账金额,接收方余额增加转账金额。等到将所有转账交易处理完毕,系统会利用 versionMap 中的 key 和对应的版本号构建合并交易的读集,利用 moneyMap 中的 key 和 value 构建合并交易的写集。
在此例中,排序节点读取 T1 的读写集,由于 T1 已经在前一阶段被识别为转账交易,排序节点首先记录读集中 A 和 B 的初始值,然后根据写集 A 和 B 值的变化推测出转账金额,将 A 的值减 10,B 的值加 10,若此时余额不足则将交易中止。同理操作 T2,只不过在记录初始值时忽略已经存在的 B。最终得到合并交易的读写集如 Table 7 所示。由于验证阶段只对合并交易的读写集验证一次,因此 T1 和 T2 对账本状态的修改都可以生效。

合并交易构建完成后,系统会在出块时将其放在区块第一笔交易的位置,并将被合并的转账交易依次放在其之后的位置。在区块中保留被合并的交易有两点好处:一是为了在验证合并交易后将交易成功与否的信息反馈给客户端,二是将交易数据保留在链上以便日后的审查。在验证阶段,节点检测到合并交易会对其进行有效性的验证,若通过验证则依次将交易成功的信息反馈给发送被合并交易的客户端,否则返回错误信息并将所有被合并交易标记为无效。
4.4 Caching Mechanism
为了缓解 3.2 节中提到的 Cross-block conflicts 读写冲突问题,我们在排序节点使用哈希表实现了一个缓存,用于缓存收到交易的读写集中的 key 和版本号。缓存表中一共包含 key、version 和 updated 三个字段,其中哈希表的 key 是智能合约链码中某实体的唯一名称,version 表示对应 key 在交易中读取到的最新版本号,由区块号和交易号形成的二元组表示,updated 字段则表示对应的 key 是否有可能被新的区块所更新。该缓存在交易到达排序节点时,会检查每一笔交易的读集。若读集中的某个 key 小于缓存中的版本号,则直接将交易中止,这可以防止由于网络中某些陈旧的交易占用系统资源。若读集中的某个 key 大于缓存中的版本号,或不存在于缓存,则更新缓存储存最新的版本号。若读集中的某个 key 等于缓存中的版本号,则看其是否有 updated 标记,若有则中止交易。在进行完重排序后,排序节点得到了一个包含无冲突交易排序的区块,系统正常运行下,这个区块的写集都会被应用于账本的更新。此时排序节点会检查每一笔交易的读集,若缓存中包含与读集相同的 key,则在缓存对应的值中加上 updated 标记。这表示该 key 已被更新,该版本已不是此 key 的最新版本。
如 Figure 7 所示,T1 和 T2 是处在不同区块中的两笔交易。在执行交易时,T1 读取 k1 的当前版本号 v0 并加入其读集,此时节点的本地状态并未发生变化,T2 也读取了 k1 和其版本号 v0。在排序阶段,当读取到 T1 读集中的 k1 时,orderer 将其与缓存中的值进行比较并发现缓存中不存在 k1,于是将 k1:v0 加入缓存。经过重排序后,orderer 再次检查交易序列,发现 k1 出现在序列交易的读集中,于是将缓存更新为 k1:v0-updated,表示当前节点的帐本中 k1 的版本大于 v0。随后包含交易 T2 的区块到来,orderer 检测到其读集中 k1 的版本为 v0,而缓存中 k1 的版本为 v0-updated,于是中止 T2。
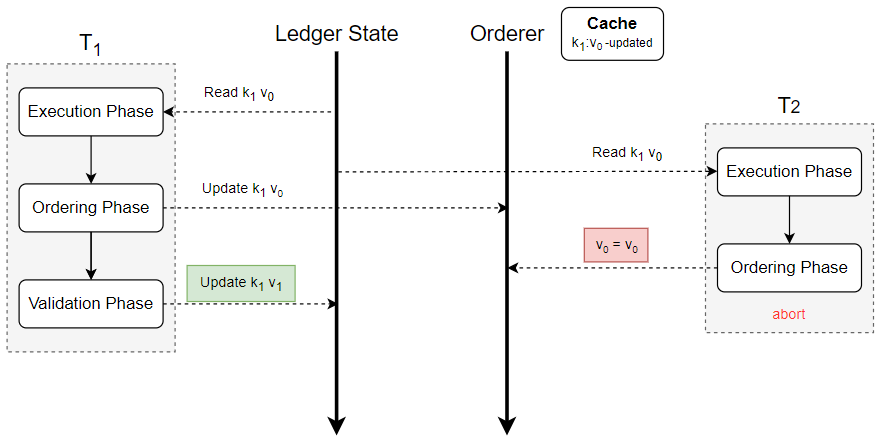
使用此缓存机制存在一个问题,假如上述示例中 T1 由于某些意外原因(如签名问题)未能通过最终的验证阶段。此时节点世界状态中 k1 的版本号依旧为 v0,但是 orderer 中 k1 的版本号已经被更新为 v0-updated,这会导致后续读取 k1 的交易都无法通过。针对这一问题,我们在 orderer 的缓存中加入计时器,如果某个 key 在一个出块间隔时间内未被更新,则将其移出缓存。这同时也保证了缓存所占空间不会无限制增加。
5 Experimental Evaluation
为了验证本文提出改进方案的有效性,我们基于 Fabric v2.4 实现了第四章提出的改进方案,并将系统命名为 FabricMan。由于原本的 Fabric++ 代码是基于 Fabric v1.2 实现的,为了方便对比,我们同样基于 Fabric v2.4 实现了 Fabric++ 的改进。并且在本章对 Fabric、Fabric++ 和 FabricMan 等三个系统在吞吐量、交易成功率、算法运行时间等关键指标上开展实验评估工作。
5.1 Setup and Workload
本文实验场景为单通道区块链系统,其中包含 2 个组织,每个组织包含 2 个对等节点,节点通过 Docker 容器部署。共识机制采用 Raft 共识,并使用 LevelDB 作为状态数据库。实验使用 1 台 36 核 CPU(Intel Core i9-10980XE 3.0GHz) 服务器进行,256GB RAM,并运行在 Ubuntu 20.04.5 LTS 环境下。
实验采用 Smallbank 和自定义链码两种工作负载,并在 caliper-benchmarks 测试框架下进行测试。Smallbank 合约为每个用户创建一个支票账户和一个储蓄账户,包括六个函数,其中五个以某种方式更新账户余额:TransactSavings 和 DepositChecking 分别增加储蓄账户和支票账户的一定金额。SendPayment 在两个支票账户之间转移资金。WriteCheck 减少支票账户余额,而 Amalgamate 将所有资金从储蓄账户转移到支票账户。此外,还有一个只读事务 Query,它读取用户的支票账户和储蓄账户。在单次运行中,我们以相同的概率随机运行这六种函数中的一个,并随机选取某个或某两个系统中存在的账户进行交易。通过改变系统中账户数量,来控制区块内可能产生交易冲突的概率。而在自定义链码中我们定义了复杂读写交易,从系统中读取四个账户的余额并对其中两个进行修改,这涉及到四个账户的读和两个账户的写。
在第 3 章中我们使用 Smallbank 对 Fabric 测试了在不同账户数量情况下有效交易和中止交易吞吐量的情况,可以得到不同账户对应的交易冲突率情况如 Table 8 所示。在后续实验中我们依旧采用该实验中账户数量取值,用于测量系统在不同交易冲突率情况下的表现。

5.2 The Impact of Block Size
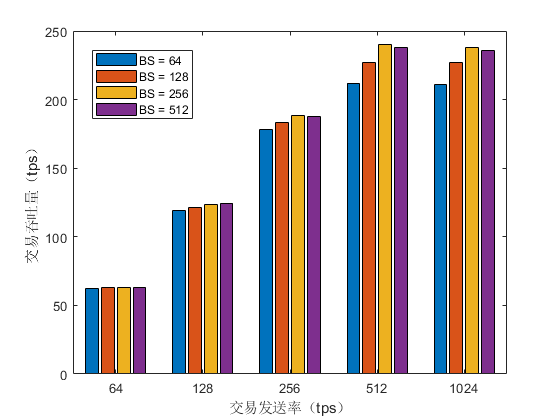
区块大小是影响区块链吞吐量和延迟的重要因素之一,我们首先测试改变区块大小对 Fabric、Fabric++ 和 FabricMan 吞吐量的影响。我们使用 Smallbank 合约,并在系统账户为 3000 时的低冲突率环境下完成这个实验。第一步我们改变 FabricMan 的区块大小(BS)从 64 到 512 ,测试其在不同交易发送率下的吞吐量,结果如 Figure 8 所示。我们发现随着交易发送率增加,系统吞吐量也逐渐提升,直到大约 240 tps 时达到饱和。此时的交易发送率为 512,后续实验采用该发送率发送交易以测得系统最佳性能。随着区块大小从 64 增加到 256,系统吞吐量也有所增加,而区块大小为 512 时,系统吞吐量下降。这是因为增加区块中的交易数会导致冲突交易变多,减少成功交易的吞吐量,并且较大的区块在系统中传输时间也会增加。
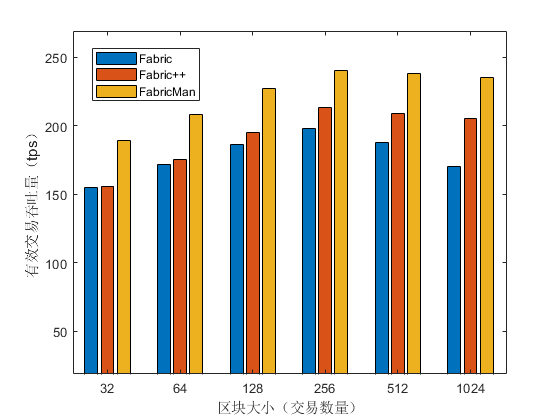
我们对另外两个对比系统也进行了类似的实验,区块大小对三个系统吞吐量的影响如 Figure 9 所示。可以看出随着区块内交易数量增加,FabricMan 和 Fabric++ 中成功交易的吞吐量与 Fabric 差距越大。这是因为同一区块内交易数量越多,发生冲突概率越大,重排作用越明显。在区块大小为 256 时三个系统吞吐量都到达峰值,因此在后续实验中,我们使用 256 作为区块中包含交易的最大数量,设置最大出块间隔为 1 秒,并将交易发送率设置为每秒 512 笔。
5.3 The Comparison of Reordering Algorithm
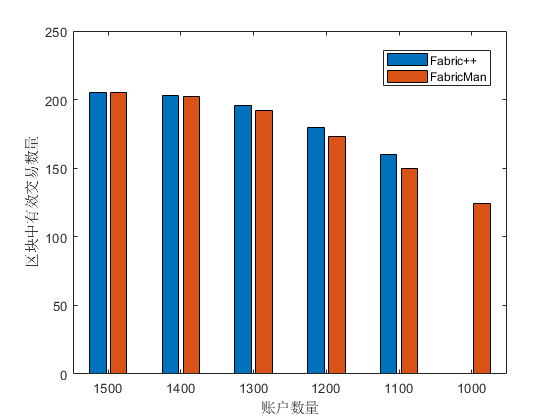
为了检测本文提出的重排序算法性能,我们准备了多个打包好的区块(每个区块中包含 256 笔交易),分别使用 FabricMan 和 Fabric++ 的重排序算法进行重排序,比较其排序时间和区块内最终有效交易的数量以及有效交易的吞吐量。在此实验中我们使用自定义链码的复杂读写交易来提高交易之间的关联性和冲突率,以更好的检测两种算法性能。我们控制系统中账户数量从 1500 逐步减少到 1000,Figure 10 显示了两种算法对区块进行重排序的时间。可以看出 Fabric++ 在区块内冲突率增加时所需时间增长明显,在账户数量为 1000 的时候已经无法正常出块。
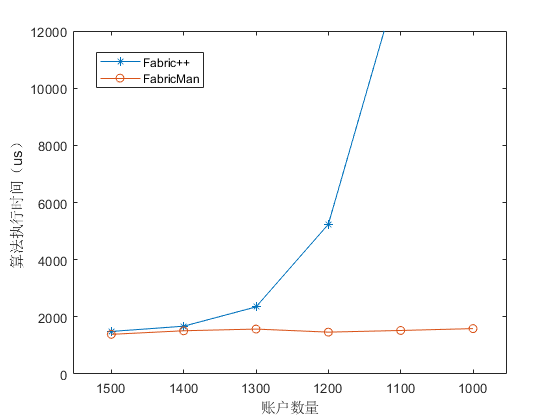
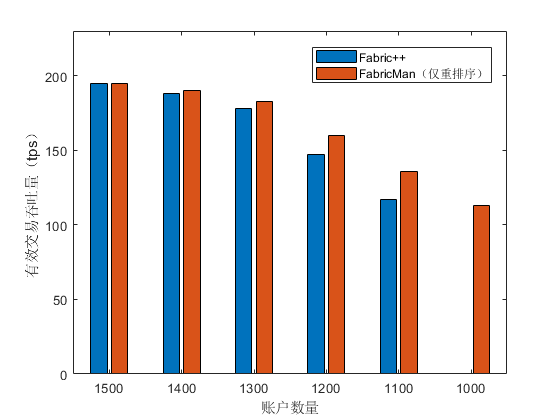
并且实验中我们发现在同一轮次实验中(账户数量相同时),Fabric++ 在不同区块排序时间差别巨大。而 FabricMan 重排算法时间稳定在 1500us 左右,不随着区块内交易冲突增加而发生明显变化。但是由于 FabricMan 的重排算法并不能像 Fabric++ 一样在每一轮选出存在最多环中的节点,所以最终成功交易略少于 Fabric++ 中的区块,如 Figure 11 所示。但是其稳定的时间复杂度可以让它在 1000 及以下账户数量的高冲突率环境中依旧正常出块。
最后我们比较了两系统在吞吐量上的差异,结果如 Figure 12 所示,实验中 FabricMan 仅加入了重排序模块的优化。我们发现 FabricMan 在各个账户数量的设置下,吞吐量均高于 Fabric++。这是因为在账户数量为 1300 到 1400 时区块内冲突率较低,同一区块内两种排序算法得到的有效交易数量相当,但是 FabricMan 重排序算法有更短的排序时间。当账户数量小于 1400 时,系统冲突率增加明显,虽然 Fabric++ 重排序算法可以得到更多的有效交易,但是其重排序所花时间增长显著。
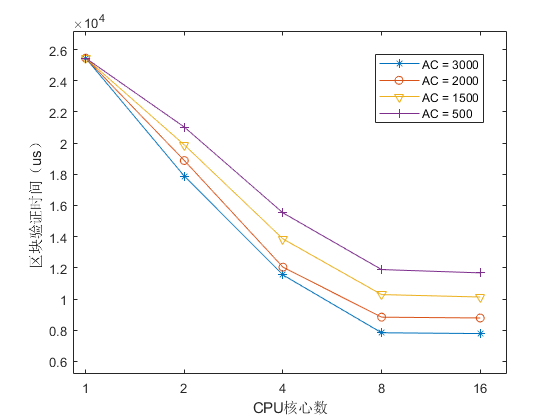
5.4 The Effect of Parallel Verification
本节我们测试给 FabricMan 验证节点分配不同的 CPU 核心数量对并行验证时间的影响。由于许可区块链在进行节点身份的加密和解密运算时同样需要使用大量的 CPU 资源,这会影响到我们的实验结果。为了消除该部分的影响,我们使用多个打包好的区块,分别在 CPU 核心数为 1 到 16 的验证节点进行 MVCC 验证时间的模块化测试。实验使用 Smallbank 合约,并设置不同的账户数量(AC)表示不同的冲突率。为了使在不同冲突率下验证的交易数一致,本实验在出块时不采用重排序,仅使用交易子图的划分算法。测试结果如 Figure 13 所示,可以看出随着使用的核心数的增加,不同冲突率区块的 MVCC 验证时间有明显减少。而核心数到达 8 以上时间减少不明显,这是因为该阶段与数据库交互和最长交易冲突链的串行验证成为瓶颈。区块冲突率越高时,形成的最长冲突链越长,相应的验证时间也越长。
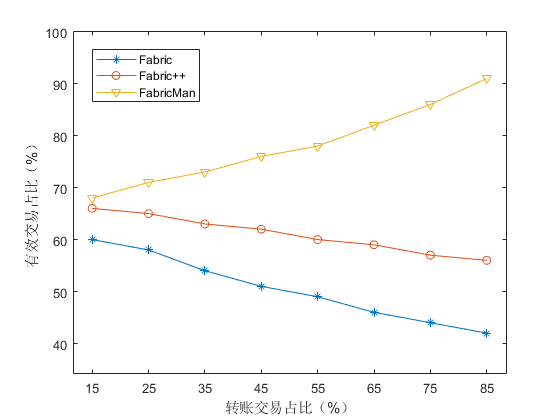
5.5 The Effect of Transaction Merging
我们使用 1000 个账户发送 Smallbank 合约中的非转账交易或转账交易,其中非转账交易交易无法合并,而转账交易是可以进行合并的。发送转账交易的占比由 15% 逐步提升至 85%,Fabric、Fabric++ 和 FabricMan 系统中成功交易的占比如 Figure 14 所示。转账交易占比较低时,Fabric++ 和 FabricMan 因为使用重排序,成功交易的比例高于 Fabric。当转账交易占比增加,FabrciMan 由于交易合并机制,成功交易比例增加,在转账交易占比为 85% 时 FabricMan 中 90% 以上的交易都可以成功提交。而由于转账交易相较于 Smallbank 中的非转账交易的读写集更复杂,交易间关联性更强,所以随着转账交易占比增加 Fabric 和 Fabric++ 中 MVCC 冲突数量增加,成功交易比例降低。
5.6 Combinations of Optimizations
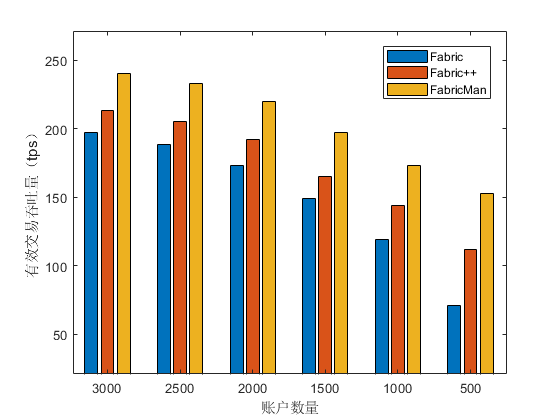
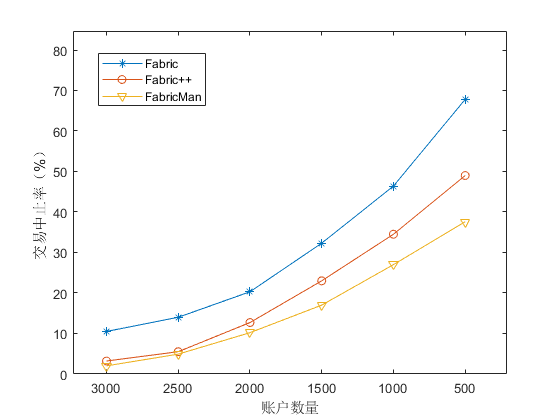
最后我们对系统的整体性能进行测试。我们使用 smallbank 合约作为工作负载,并将第四章提到的所有优化应用于 FabricMan 系统,在不同账户数量下进行测试。与 Fabric 和 Fabric++ 中有效交易的吞吐量进行对比结果如 Figure 15 所示,系统中的交易中止率如 Figure 16 所示。可见当账户数量为 3000 时,此时交易中止率较低,Fabric 的吞吐量在三个系统中最低,不到 200 tps。Fabric++ 由于重排序的作用,吞吐量略高,约为 220 tps。而 FabricMan 由于重排序和并行验证以及对其中转账交易的合并,吞吐量约为 240 tps,为三者最高。当账户数量从 3000 逐步减少到 500 时,区块内交易中止率不断增加,Fabric 的有效交易吞吐量下降严重,只有不到最初的一半。而 FabricMan 的有效吞交易吐量下降较为缓慢,且交易中止率最低,在高并发冲突环境下仍能保持较高吞吐量。
6 Conclusion
本文针对新型的 EOV 区块链并发执行交易产生 MVCC 冲突影响性能的问题,提出了一种综合考虑块内冲突和块间冲突,并且能够进行并行验证和交易合并的区块链架构 FabicMan。针对块内冲突,本文提出一种比 Fabric++ 重排序算法在时间上更加稳定的算法对区块内交易重排序,增加交易验证的成功率。同时还提出使用交易冲突图信息在验证节点对无关交易并行验证,并且对简单的资产转移交易进行交易合并的方案,从而提升 EOV 区块链系统性能。针对块间冲突,本文提出一种利用交易读写集和版本号在排序节点提前中止冲突交易的缓存机制。实验结果表明 FabricMan 在吞吐量、交易中止率、执行时间等方面均优于对比方案。
References
[1] Nakamoto S. Bitcoin: A peer-to-peer electronic cash system[J]. 2008.
[2] Buterin V. A next-generation smart contract and decentralized application platform[J]. white paper, 2014, 3(37): 2-1.
[3] Qin K, Zhou L, Gervais A. Quantifying blockchain extractable value: How dark is the forest?[C]//2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022: 198-214.
[4] Azaria A, Ekblaw A, Vieira T, et al. Medrec: Using blockchain for medical data access and permission management[C]//2016 2nd international conference on open and big data (OBD). IEEE, 2016: 25-30.
[5] Fan K, Wang S, Ren Y, et al. Medblock: Efficient and secure medical data sharing via blockchain[J]. Journal of medical systems, 2018, 42: 1-11.
[6] Abeyratne S A, Monfared R P. Blockchain ready manufacturing supply chain using distributed ledger[J]. International journal of research in engineering and technology, 2016, 5(9): 1-10.
[7] Dai H N, Zheng Z, Zhang Y. Blockchain for Internet of Things: A survey[J]. IEEE internet of things journal, 2019, 6(5): 8076-8094.
[8] Vukolić M. The quest for scalable blockchain fabric: Proof-of-work vs. BFT replication[C]//Open Problems in Network Security: IFIP WG 11.4 International Workshop, iNetSec 2015, Zurich, Switzerland, October 29, 2015, Revised Selected Papers. Springer International Publishing, 2016: 112-125.
[9] Charron-Bost B, Pedone F, Schiper A. Replication[M]. Springer Berlin Heidelberg, 2010.
[10] Papadimitriou C H, Kanellakis P C. On concurrency control by multiple versions[J]. ACM Transactions on Database Systems (TODS), 1984, 9(1): 89-99.
[11] Sharma A, Schuhknecht F M, Agrawal D, et al. Blurring the lines between blockchains and database systems: the case of hyperledger fabric[C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 105-122.
[12] Androulaki E, Barger A, Bortnikov V, et al. Hyperledger fabric: a distributed operating system for permissioned blockchains[C]//Proceedings of the thirteenth EuroSys conference. 2018: 1-15.
[13] Tarjan R. Depth-first search and linear graph algorithms[J]. SIAM journal on computing, 1972, 1(2): 146-160.
[14] Johnson D B. Finding all the elementary circuits of a directed graph[J]. SIAM Journal on Computing, 1975, 4(1): 77-84.
[15] Dinh T T A, Wang J, Chen G, et al. Blockbench: A framework for analyzing private blockchains[C]//Proceedings of the 2017 ACM international conference on management of data. 2017: 1085-1100.
[16] Baliga A, Solanki N, Verekar S, et al. Performance characterization of hyperledger fabric[C]//2018 Crypto Valley conference on blockchain technology (CVCBT). IEEE, 2018: 65-74.
[17] Shalaby S, Abdellatif A A, Al-Ali A, et al. Performance evaluation of hyperledger fabric[C]//2020 IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT). IEEE, 2020: 608-613.
[18] Sukhwani H, Wang N, Trivedi K S, et al. Performance modeling of hyperledger fabric (permissioned blockchain network)[C]//2018 IEEE 17th international symposium on network computing and applications (NCA). IEEE, 2018: 1-8.
[19] Jiang L, Chang X, Liu Y, et al. Performance analysis of Hyperledger Fabric platform: A hierarchical model approach[J]. Peer-to-Peer Networking and Applications, 2020, 13: 1014-1025.
[20] Andola N, Gogoi M, Venkatesan S, et al. Vulnerabilities on hyperledger fabric[J]. Pervasive and Mobile Computing, 2019, 59: 101050.
[21] Yamashita K, Nomura Y, Zhou E, et al. Potential risks of hyperledger fabric smart contracts[C]//2019 IEEE International Workshop on Blockchain Oriented Software Engineering (IWBOSE). IEEE, 2019: 1-10.
[22] Brandenburger M, Cachin C, Kapitza R, et al. Blockchain and trusted computing: Problems, pitfalls, and a solution for hyperledger fabric[J]. arXiv preprint arXiv:1805.08541, 2018.
[23] Dabholkar A, Saraswat V. Ripping the fabric: Attacks and mitigations on hyperledger fabric[C]//Applications and Techniques in Information Security: 10th International Conference, ATIS 2019, Thanjavur, India, November 22–24, 2019, Proceedings 10. Springer Singapore, 2019: 300-311.
[24] Thakkar P, Nathan S, Viswanathan B. Performance benchmarking and optimizing hyperledger fabric blockchain platform[C]//2018 IEEE 26th international symposium on modeling, analysis, and simulation of computer and telecommunication systems (MASCOTS). IEEE, 2018: 264-276.
[25] Gorenflo C, Lee S, Golab L, et al. FastFabric: Scaling hyperledger fabric to 20 000 transactions per second[J]. International Journal of Network Management, 2020, 30(5): e2099.
[26] Ruan P, Loghin D, Ta Q T, et al. A transactional perspective on execute-order-validate blockchains[C]//Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020: 543-557.
[27] Sun Q, Yuan Y, Guo T, et al. A Trusted Solution to Hyperledger Fabric Reordering Problem[C]//2021 8th International Conference on Dependable Systems and Their Applications (DSA). IEEE, 2021: 202-207.
[28] Wu H, Liu H, Li J. FabricETP: A high-throughput blockchain optimization solution for resolving concurrent conflicting transactions[J]. Peer-to-Peer Networking and Applications, 2023, 16(2): 858-875.
[29] Garamvölgyi P, Liu Y, Zhou D, et al. Utilizing parallelism in smart contracts on decentralized blockchains by taming application-inherent conflicts[C]//Proceedings of the 44th International Conference on Software Engineering. 2022: 2315-2326.